2. Introduction to Machine Learning#
In this chapter, we’ll briefly review machine learning concepts that will be relevant later. We’ll focus in particular on the problem of prediction, that is, to model some output variable as a function of observed input covariates.
# importing the packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import random
import math
import warnings
from sklearn.metrics import mean_squared_error
from SyncRNG import SyncRNG
warnings.filterwarnings('ignore')
%matplotlib inline
In this section, we will use simulated data. In the next section we’ll load a real dataset.
# Simulating data
# Sample size
n = 500
# Generating covariate X ~ Unif[-4, 4]
x = np.linspace(-4,4, n) #with linspace we can generate a vector of "n" numbers between a range of numbers
random.shuffle(x)
mu = np.where(x<0, np.cos(2*x), 1 - np.sin(x) )
y = mu + 1*np.random.normal(size =n)
# collecting observations in a data.frame object
data = pd.DataFrame(np.array([x,y]).T, columns=['x','y'])
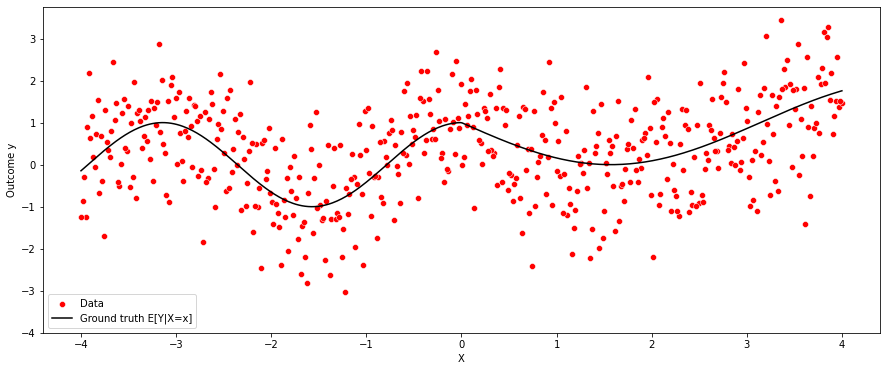
The following shows how the two variables x and y relate. Note that the relationship is nonlinear.
plt.figure(figsize=(15,6))
sns.scatterplot(x,y, color = 'red', label = 'Data')
sns.lineplot(x,mu, color = 'black', label = "Ground truth E[Y|X=x]")
plt.yticks(np.arange(-4,4,1))
plt.legend()
plt.xlabel("X")
plt.ylabel("Outcome y")
Text(0, 0.5, 'Outcome y')
Note: If you’d like to run the code below on a different dataset, you can replace the dataset above with another data.frame of your choice, and redefine the key variable identifiers (outcome, covariates) accordingly. Although we try to make the code as general as possible, you may also need to make a few minor changes to the code below; read the comments carefully.
2.1. Key concepts#
The prediction problem is to accurately guess the value of some output variable \(Y_i\) from input variables \(X_i\). For example, we might want to predict “house prices given house characteristics such as the number of rooms, age of the building, and so on. The relationship between input and output is modeled in very general terms by some function
where \(\epsilon_i\) represents all that is not captured by information obtained from \(X_i\) via the mapping \(f\). We say that error \(\epsilon_i\) is irreducible.
We highlight that (2.1) is not modeling a causal relationship between inputs and outputs. For an extreme example, consider taking \(Y_i\) to be “distance from the equator” and \(X_i\) to be “average temperature.” We can still think of the problem of guessing (“predicting”) “distance from the equator” given some information about “average temperature,” even though one would expect the former to cause the latter.
In general, we can’t know the “ground truth” \(f\), so we will approximate it from data. Given \(n\) data points \(\{(X_1, Y_1), \cdots, (X_n, Y_n)\}\), our goal is to obtain an estimated model \(\hat{f}\) such that our predictions \(\widehat{Y}_i := \hat{f}(X_i)\) are “close” to the true outcome values \(Y_i\) given some criterion. To formalize this, we’ll follow these three steps:
Modeling: Decide on some suitable class of functions that our estimated model may belong to. In machine learning applications the class of functions can be very large and complex (e.g., deep decision trees, forests, high-dimensional linear models, etc). Also, we must decide on a loss function that serves as our criterion to evaluate the quality of our predictions (e.g., mean-squared error).
Fitting: Find the estimate \(\hat{f}\) that optimizes the loss function chosen in the previous step (e.g., the tree that minimizes the squared deviation between \(\hat{f}(X_i)\) and \(Y_i\) in our data).
Evaluation: Evaluate our fitted model \(\hat{f}\). That is, if we were given a new, yet unseen, input and output pair \((X',Y')\), we’d like to know if \(Y' \approx \hat{f}(X_i)\) by some metric.
For concreteness, let’s work through an example. Let’s say that, given the data simulated above, we’d like to predict \(Y_i\) from the first covariate \(X_{i1}\) only. Also, let’s say that our model class will be polynomials of degree \(q\) in \(X_{i1}\), and we’ll evaluate fit based on mean squared error. That is, \(\hat{f}(X_{i1}) = \hat{b}_0 + X_{i1}\hat{b}_1 + \cdots + X_{i1}^q \hat{b}_q\), where the coefficients are obtained by solving the following problem:
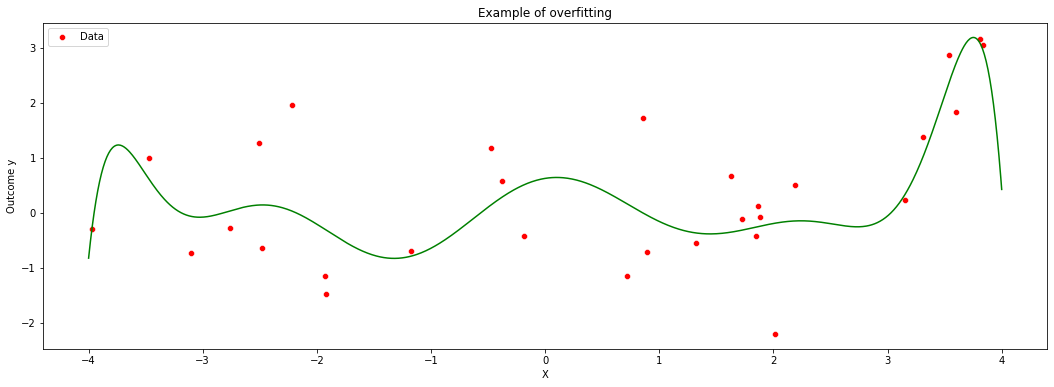
An important question is what is \(q\), the degree of the polynomial. It controls the complexity of the model. One may imagine that more complex models are better, but that is not always true, because a very flexible model may try to simply interpolate over the data at hand, but fail to generalize well for new data points. We call this overfitting. The main feature of overfitting is high variance, in the sense that, if we were given a different data set of the same size, we’d likely get a very different model.
To illustrate, in the figure below we let the degree be \(q=10\) but use only the first few data points. The fitted model is shown in green, and the original data points are in red.
X = data.loc[:,'x'].values.reshape(-1, 1)
Y = data.loc[:,'y'].values.reshape(-1, 1)
# Note: this code assumes that the first covariate is continuous.
# Fitting a flexible model on very little data
# selecting only a few data points
subset = np.arange(0,30)
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.model_selection import train_test_split
poly = PolynomialFeatures(degree = 10)
X_poly = poly.fit_transform(X)
poly.fit(X_poly, Y)
lin2 = LinearRegression()
lin2.fit(X_poly[0:30], Y[0:30])
x = data['x']
xgrid = np.linspace(min(x),max(x), 1000)
new_data = pd.DataFrame(xgrid, columns=['x'])
yhat = lin2.predict(poly.fit_transform(new_data))
# Visualising the Polynomial Regression results
plt.figure(figsize=(18,6))
sns.scatterplot(data.loc[subset,'x'],data.loc[subset,'y'], color = 'red', label = 'Data')
plt.plot(xgrid, yhat, color = 'green', label = 'Estimate')
plt.title('Example of overfitting')
plt.xlabel('X')
plt.ylabel('Outcome y')
Text(0, 0.5, 'Outcome y')
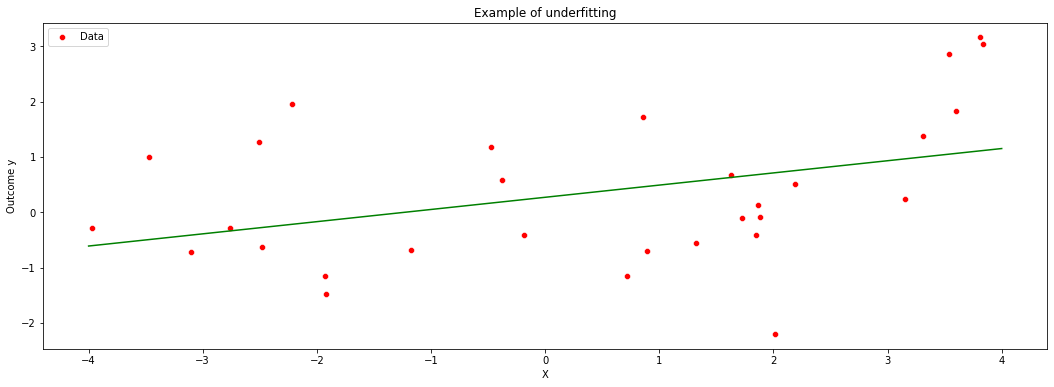
On the other hand, when \(q\) is too small relative to our data, we permit only very simple models and may suffer from misspecification bias. We call this underfitting. The main feature of underfitting is high bias – the selected model just isn’t complex enough to accurately capture the relationship between input and output variables.
To illustrate underfitting, in the figure below we set \(q=1\) (a linear fit).
lin = LinearRegression()
lin.fit(X[0:30], Y[0:30])
x = data['x']
xgrid = np.linspace(min(x),max(x), 1000)
new_data = pd.DataFrame(xgrid, columns=['x'])
yhat = lin.predict(new_data)
plt.figure(figsize=(18,6))
sns.scatterplot(data.loc[subset,'x'],data.loc[subset,'y'], color = 'red', label = 'Data')
plt.plot(xgrid, yhat, color = 'green',label = 'Estimate')
plt.title('Example of underfitting')
plt.xlabel('X')
plt.ylabel('Outcome y')
Text(0, 0.5, 'Outcome y')
This tension is called the bias-variance trade-off: simpler models underfit and have more bias, more complex models overfit and have more variance.
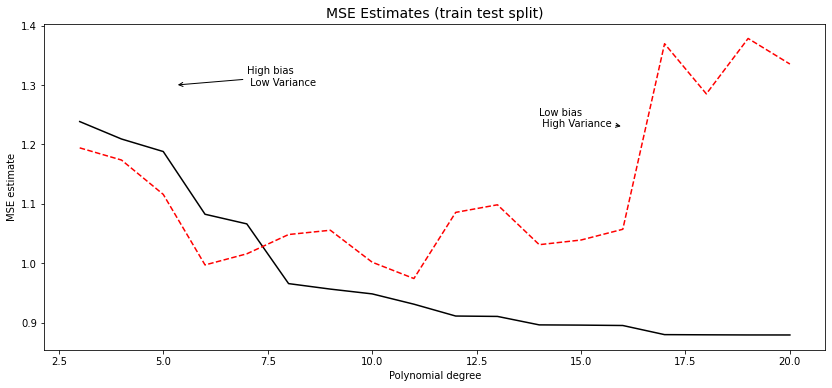
One data-driven way of deciding an appropriate level of complexity is to divide the available data into a training set (where the model is fit) and the validation set (where the model is evaluated). The next snippet of code uses the first half of the data to fit a polynomial of order \(q\), and then evaluates that polynomial on the second half. The training MSE estimate decreases monotonically with the polynomial degree, because the model is better able to fit on the training data; the test MSE estimate starts increasing after a while reflecting that the model no longer generalizes well.
degrees =np.arange(3,21)
train_mse =[]
test_mse =[]
for d in degrees:
poly =PolynomialFeatures(degree = d, include_bias =False )
poly_features = poly.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(poly_features,y, train_size=0.5 , random_state= 0)
# Now since we want the valid and test size to be equal (10% each of overall data).
# we have to define valid_size=0.5 (that is 50% of remaining data)
poly_reg_model = LinearRegression()
poly_reg_model.fit(X_train, y_train)
y_train_pred = poly_reg_model.predict(X_train)
y_test_pred = poly_reg_model.predict(X_test)
mse_train= mean_squared_error(y_train, y_train_pred)
mse_test= mean_squared_error(y_test, y_test_pred)
train_mse.append(mse_train)
test_mse.append(mse_test)
fig, ax = plt.subplots(figsize=(14,6))
ax.plot(degrees, train_mse,color ="black", label = "Training")
ax.plot(degrees, test_mse,"r--", label = "Validation")
ax.set_title("MSE Estimates (train test split)", fontsize =14)
ax.set(xlabel = "Polynomial degree", ylabel = "MSE estimate")
ax.annotate("Low bias \n High Variance", xy=(16, 1.23), xycoords='data', xytext=(14, 1.23), textcoords='data',
arrowprops=dict(arrowstyle="->",connectionstyle="arc3"),)
ax.annotate("High bias \n Low Variance", xy=(5.3, 1.30), xycoords='data', xytext=(7, 1.30), textcoords='data',
arrowprops=dict(arrowstyle="->",connectionstyle="arc3"),)
Text(7, 1.3, 'High bias \n Low Variance')
To make better use of the data we will often divide the data into \(K\) subsets, or folds. Then one fits \(K\) models, each using \(K-1\) folds and then evaluation the fitted model on the remaining fold. This is called k-fold cross-validation.
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
#cv = KFold(n_splits=10, random_state=1, shuffle=True)
scorer = make_scorer
mse =[]
for d in degrees:
poly =PolynomialFeatures(degree = d, include_bias =False )
poly_features = poly.fit_transform(X)
ols = LinearRegression()
scorer = make_scorer(mean_squared_error)
mse_test= cross_val_score(ols, poly_features, y, scoring=scorer, cv =5).mean()
mse.append(mse_test)
plt.figure(figsize=(12,6))
plt.plot(degrees, mse)
plt.xlabel('Polynomial degree', fontsize = 14)
plt.xticks(np.arange(5,21,5))
plt.ylabel('MSE estimate', fontsize = 14)
plt.title('MSE estimate (K-fold cross validation)', fontsize =16)
#different to r, the models in python got a better performance with more training cause by the
#cross validation and the kfold
Text(0.5, 1.0, 'MSE estimate (K-fold cross validation)')
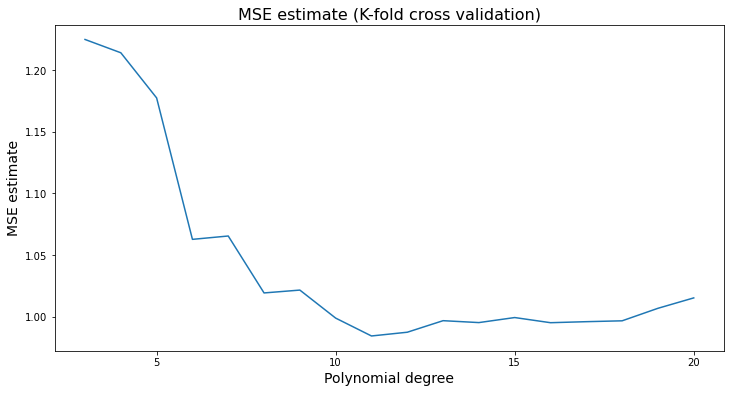
A final remark is that, in machine learning applications, the complexity of the model often is allowed to increase with the available data. In the example above, even though we weren’t very successful when fitting a high-dimensional model on very little data, if we had much more data perhaps such a model would be appropriate. The next figure again fits a high order polynomial model, but this time on many data points. Note how, at least in data-rich regions, the model is much better behaved, and tracks the average outcome reasonably well without trying to interpolate wildly of the data points.
X = data.loc[:,'x'].values.reshape(-1, 1)
Y = data.loc[:,'y'].values.reshape(-1, 1)
subset = np.arange(0,500)
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree = 15)
X_poly = poly.fit_transform(X)
poly.fit(X_poly, Y)
lin2 = LinearRegression()
lin2.fit(X_poly[0:500], Y[0:500])
x = data['x']
xgrid = np.linspace(min(x),max(x), 1000)
new_data = pd.DataFrame(xgrid, columns=['x'])
yhat = lin2.predict(poly.fit_transform(new_data))
# Visualising the Polynomial Regression results
plt.figure(figsize=(18,6))
sns.scatterplot(data.loc[subset,'x'],data.loc[subset,'y'], color = 'red', label = 'Data')
plt.plot(xgrid, yhat, color = 'green', label = 'Estimate')
sns.lineplot(x,mu, color = 'black', label = "Ground truth")
plt.xlabel('X')
plt.ylabel('Outcome')
Text(0, 0.5, 'Outcome')
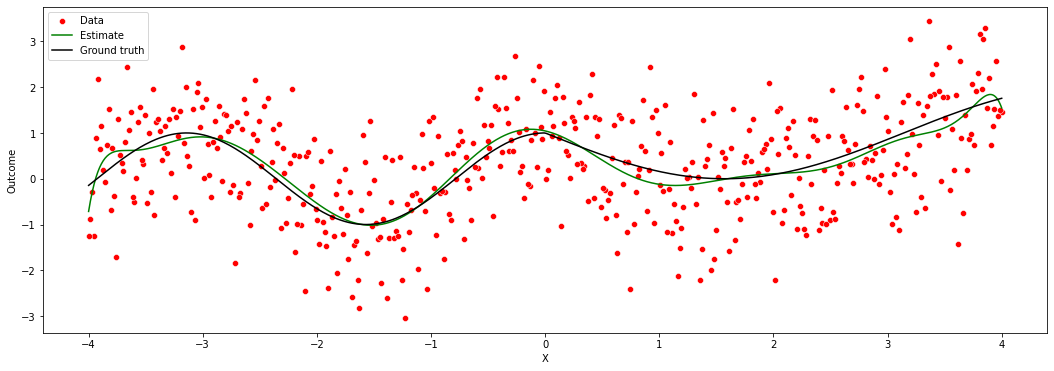
This is one of the benefits of using machine learning-based models: more data implies more flexible modeling, and therefore potentially better predictive power – provided that we carefully avoid overfitting.
The example above based on polynomial regression was used mostly for illustration. In practice, there are often better-performing algorithms. We’ll see some of them next.
2.2. Common machine learning algorithms#
Next, we’ll introduce three machine learning algorithms: (regularized) linear models, trees, and forests. Although this isn’t an exhaustive list, these algorithms are common enough that every machine learning practitioner should know about them. They also have convenient R packages that allow for easy coding.
In this tutorial, we’ll focus heavily on how to interpret the output of machine learning models – or, at least, how not to mis-interpret it. However, in this chapter we won’t be making any causal claims about the relationships between variables yet. But please hang tight, as estimating causal effects will be one of the main topics presented in the next chapters.
For the remainder of the chapter we will use a real dataset. Each row in this data set represents the characteristics of a owner-occupied housing unit. Our goal is to predict the (log) price of the housing unit (LOGVALUE, our outcome variable) from features such as the size of the lot (LOT) and square feet area (UNITSF), number of bedrooms (BEDRMS) and bathrooms (BATHS), year in which it was built (BUILT) etc. This dataset comes from the American Housing Survey and was used in Mullainathan and Spiess (2017, JEP). In addition, we will append to this data columns that are pure noise. Ideally, our fitted model should not take them into acccount.
import requests
import io
url = 'https://docs.google.com/uc?id=1qHr-6nN7pCbU8JUtbRDtMzUKqS9ZlZcR&export=download'
urlData = requests.get(url).content
data = pd.read_csv(io.StringIO(urlData.decode('utf-8')))
data.drop(['Unnamed: 0'], axis=1, inplace=True)
# outcome variable name
outcome = 'LOGVALUE'
# covariates
true_covariates = ['LOT','UNITSF','BUILT','BATHS','BEDRMS','DINING','METRO','CRACKS','REGION','METRO3','PHONE','KITCHEN','MOBILTYP','WINTEROVEN','WINTERKESP','WINTERELSP','WINTERWOOD','WINTERNONE','NEWC','DISH','WASH','DRY','NUNIT2','BURNER','COOK','OVEN','REFR','DENS','FAMRM','HALFB','KITCH','LIVING','OTHFN','RECRM','CLIMB','ELEV','DIRAC','PORCH','AIRSYS','WELL','WELDUS','STEAM','OARSYS']
p_true = len(true_covariates)
# noise covariates added for didactic reasons
p_noise = 20
noise_covariates = []
for x in range(1, p_noise+1):
noise_covariates.append('noise{0}'.format(x))
covariates = true_covariates + noise_covariates
x_noise = np.random.rand(data.shape[0] * p_noise).reshape(28727,20)
x_noise = pd.DataFrame(x_noise, columns=noise_covariates)
data = pd.concat([data, x_noise], axis=1)
# sample size
n = data.shape[0]
# total number of covariates
p = len(covariates)
Here’s the correlation between the first few covariates. Note how, most variables are positively correlated, which is expected since houses with more bedrooms will usually also have more bathrooms, larger area, etc.
data.loc[:,covariates[0:8]].corr()
| LOT | UNITSF | BUILT | BATHS | BEDRMS | DINING | METRO | CRACKS | |
|---|---|---|---|---|---|---|---|---|
| LOT | 1.000000 | 0.064841 | 0.044639 | 0.057325 | 0.009626 | -0.015348 | 0.136258 | 0.016851 |
| UNITSF | 0.064841 | 1.000000 | 0.143201 | 0.428723 | 0.361165 | 0.214030 | 0.057441 | 0.033548 |
| BUILT | 0.044639 | 0.143201 | 1.000000 | 0.434519 | 0.215109 | 0.037468 | 0.323703 | 0.092390 |
| BATHS | 0.057325 | 0.428723 | 0.434519 | 1.000000 | 0.540230 | 0.259457 | 0.189812 | 0.062819 |
| BEDRMS | 0.009626 | 0.361165 | 0.215109 | 0.540230 | 1.000000 | 0.281846 | 0.121331 | 0.026779 |
| DINING | -0.015348 | 0.214030 | 0.037468 | 0.259457 | 0.281846 | 1.000000 | 0.022026 | 0.021270 |
| METRO | 0.136258 | 0.057441 | 0.323703 | 0.189812 | 0.121331 | 0.022026 | 1.000000 | 0.057545 |
| CRACKS | 0.016851 | 0.033548 | 0.092390 | 0.062819 | 0.026779 | 0.021270 | 0.057545 | 1.000000 |
2.2.1. Generalized linear models#
This class of models extends common methods such as linear and logistic regression by adding a penalty to the magnitude of the coefficients. Lasso penalizes the absolute value of slope coefficients. For regression problems, it becomes
Similarly, in a regression problem Ridge penalizes the sum of squares of the slope coefficients,
Also, there exists the Elastic Net penalization which consists of a convex combination between the other two. In all cases, the scalar parameter \(\lambda\) controls the complexity of the model. For \(\lambda=0\), the problem reduces to the “usual” linear regression. As \(\lambda\) increases, we favor simpler models. As we’ll see below, the optimal parameter \(\lambda\) is selected via cross-validation.
An important feature of Lasso-type penalization is that it promotes sparsity – that is, it forces many coefficients to be exactly zero. This is different from Ridge-type penalization, which forces coefficients to be small.
Another interesting property of these models is that, even though they are called “linear” models, this should actually be understood as linear in transformations of the covariates. For example, we could use polynomials or splines (continuous piecewise polynomials) of the covariates and allow for much more flexible models.
In fact, because of the penalization term, problems (2.2) and (2.3) remain well-defined and have a unique solution even in high-dimensional problems in which the number of coefficients \(p\) is larger than the sample size \(n\) – that is, our data is “fat” with more columns than rows. These situations can arise either naturally (e.g. genomics problems in which we have hundreds of thousands of gene expression information for a few individuals) or because we are including many transformations of a smaller set of covariates.
Finally, although here we are focusing on regression problems, other generalized linear models such as logistic regression can also be similarly modified by adding a Lasso, Ridge, or Elastic Net-type penalty to similar consequences.
X = data.loc[:,covariates]
Y = data.loc[:,outcome]
from sklearn.linear_model import Lasso
lasso = Lasso()
alphas = np.logspace(np.log10(1e-8), np.log10(1e-1), 100)
tuned_parameters = [{"alpha": alphas}]
n_folds = 10
scorer = make_scorer(mean_squared_error)
clf = GridSearchCV(lasso, tuned_parameters, cv=n_folds, refit=False, scoring=scorer)
clf.fit(X, Y)
scores = clf.cv_results_["mean_test_score"]
scores_std = clf.cv_results_["std_test_score"]
The next figure plots the average estimated MSE for each lambda. The red dots are the averages across all folds, and the error bars are based on the variability of mse estimates across folds. The vertical dashed lines show the (log) lambda with smallest estimated MSE (left) and the one whose mse is at most one standard error from the first (right).
data_lasso = pd.DataFrame([pd.Series(alphas, name= "alphas"), pd.Series(scores, name = "scores")]).T
best = data_lasso[data_lasso["scores"] == np.min(data_lasso["scores"])]
plt.figure().set_size_inches(8, 6)
plt.semilogx(alphas, scores, ".", color = "red")
# plot error lines showing +/- std. errors of the scores
std_error = scores_std / np.sqrt(n_folds)
plt.semilogx(alphas, scores + std_error, "b--")
plt.semilogx(alphas, scores - std_error, "b--")
# alpha=0.2 controls the translucency of the fill color
plt.fill_between(alphas, scores + std_error, scores - std_error, alpha=0.2)
plt.ylabel("CV score +/- std error")
plt.xlabel("alpha")
plt.axvline(best.iloc[0,0], linestyle="--", color=".5")
plt.xlim([alphas[0], alphas[-1]])
(1e-08, 0.1)
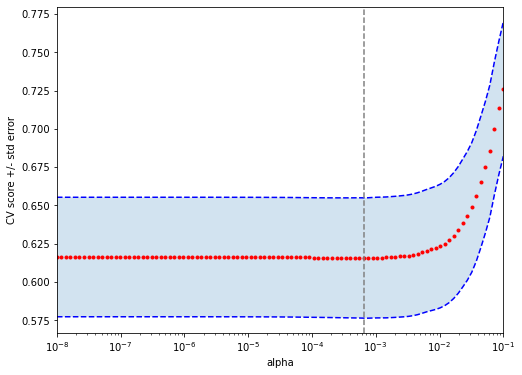
Here are the first few estimated coefficients at the \(\lambda\) value that minimizes cross-validated MSE. Note that many estimated coefficients them are exactly zero.
lasso = Lasso(alpha=best.iloc[0,0])
lasso.fit(X,Y)
table = np.zeros((1,5))
table[0,0] = lasso.intercept_
table[0,1] = lasso.coef_[0]
table[0,2] = lasso.coef_[1]
table[0,3] = lasso.coef_[2]
table[0,4] = lasso.coef_[3]
pd.DataFrame(table, columns=['(Intercept)','LOT','UNITSF','BUILT','BATHS'], index=['Coef.'])
| (Intercept) | LOT | UNITSF | BUILT | BATHS | |
|---|---|---|---|---|---|
| Coef. | 11.643421 | 3.494443e-07 | 0.000023 | 0.000229 | 0.246402 |
print("Number of nonzero coefficients at optimal lambda:", len(lasso.coef_[lasso.coef_ != 0]), "out of " , len(lasso.coef_))
Number of nonzero coefficients at optimal lambda: 46 out of 63
Predictions and estimated MSE for the selected model are retrieved as follows.
# Retrieve predictions at best lambda regularization parameter
y_hat = lasso.predict(X)
# Get k-fold cross validation
mse_lasso = best.iloc[0,1]
print("glmnet MSE estimate (k-fold cross-validation):", mse_lasso)
glmnet MSE estimate (k-fold cross-validation): 0.6156670911339063
The next command plots estimated coefficients as a function of the regularization parameter \(\lambda\).
coefs = []
for a in alphas:
lasso.set_params(alpha=a)
lasso.fit(X, Y)
coefs.append(lasso.coef_)
from matplotlib.pyplot import figure
plt.figure(figsize=(18,6))
plt.gca().plot(alphas, coefs)
plt.gca().set_xscale('log')
plt.axis('tight')
plt.xlabel('alpha')
plt.ylabel('Standardized Coefficients')
plt.title('Lasso coefficients as a function of alpha');
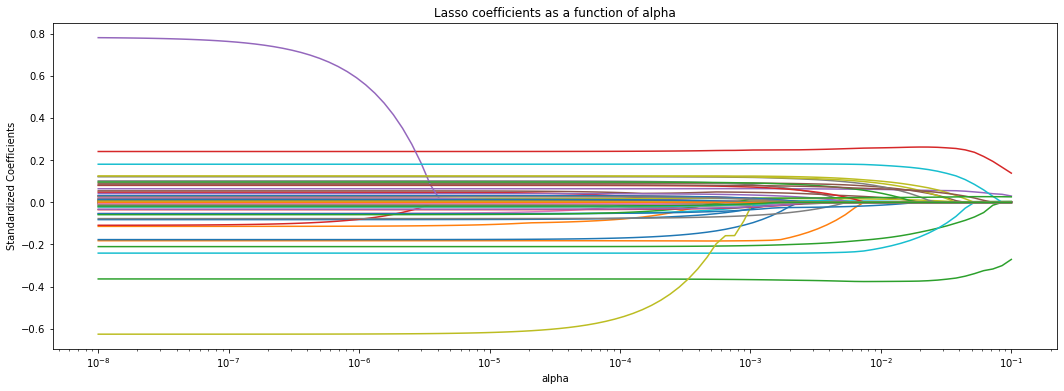
It’s tempting to try to interpret the coefficients obtained via Lasso. Unfortunately, that can be very difficult, because by dropping covariates Lasso introduces a form of omitted variable bias (wikipedia). To understand this form of bias, consider the following toy example. We have two positively correlated independent variables, x.1 and x.2, that are linearly related to the outcome y. Linear regression of y on x1 and x2 gives us the correct coefficients. However, if we omit x2 from the estimation model, the coefficient on x1 increases. This is because x1 is now “picking up” the effect of the variable that was left out. In other words, the effect of x1 seems stronger because we aren’t controlling for some other confounding variable. Note that the second model this still works for prediction, but we cannot interpret the coefficient as a measure of strength of the causal relationship between x1 and y.
mean = [0.0,0.0]
cov = [[1.5,1],[1,1.5]]
x1, x2 = np.random.multivariate_normal(mean, cov, 100000).T
y = 1 + 2*x1 + 3*x2 + np.random.rand(100000)
data_sim = pd.DataFrame(np.array([x1,x2,y]).T,columns=['x1','x2','y'] )
print('Correct Model')
Correct Model
import statsmodels.formula.api as smf
result = smf.ols('y ~ x1 + x2', data = data_sim).fit()
print(result.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.997
Model: OLS Adj. R-squared: 0.997
Method: Least Squares F-statistic: 1.897e+07
Date: Wed, 22 Jun 2022 Prob (F-statistic): 0.00
Time: 20:59:12 Log-Likelihood: -17706.
No. Observations: 100000 AIC: 3.542e+04
Df Residuals: 99997 BIC: 3.545e+04
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.5012 0.001 1643.500 0.000 1.499 1.503
x1 1.9998 0.001 1996.643 0.000 1.998 2.002
x2 3.0011 0.001 3002.007 0.000 2.999 3.003
==============================================================================
Omnibus: 90005.976 Durbin-Watson: 2.010
Prob(Omnibus): 0.000 Jarque-Bera (JB): 6016.746
Skew: -0.006 Prob(JB): 0.00
Kurtosis: 1.798 Cond. No. 2.24
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
print("Model with omitted variable bias")
result = smf.ols('y ~ x1', data = data_sim).fit()
print(result.summary())
Model with omitted variable bias
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.760
Model: OLS Adj. R-squared: 0.760
Method: Least Squares F-statistic: 3.174e+05
Date: Wed, 22 Jun 2022 Prob (F-statistic): 0.00
Time: 20:59:21 Log-Likelihood: -2.4332e+05
No. Observations: 100000 AIC: 4.866e+05
Df Residuals: 99998 BIC: 4.867e+05
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.5107 0.009 173.262 0.000 1.494 1.528
x1 4.0084 0.007 563.401 0.000 3.994 4.022
==============================================================================
Omnibus: 0.159 Durbin-Watson: 2.003
Prob(Omnibus): 0.924 Jarque-Bera (JB): 0.158
Skew: -0.003 Prob(JB): 0.924
Kurtosis: 3.001 Cond. No. 1.23
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
The phenomenon above occurs in Lasso and in any other sparsity-promoting method when correlated covariates are present since, by forcing coefficients to be zero, Lasso is effectively dropping them from the model. And as we have seen, as a variable gets dropped, a different variable that is correlated with it can “pick up” its effect, which in turn can cause bias. Once \(\lambda\) grows sufficiently large, the penalization term overwhelms any benefit of having that variable in the model, so that variable finally decreases to zero too.
One may instead consider using Lasso to select a subset of variables, and then regressing the outcome on the subset of selected variables via OLS (without any penalization). This method is often called post-lasso. Although it has desirable properties in terms of model fit (see e.g., Belloni and Chernozhukov, 2013), this procedure does not solve the omitted variable issue we mentioned above.
We illustrate this next. We observe the path of the estimated coefficient on the number of bathroooms (BATHS) as we increase \(\lambda\).
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
scale_X = StandardScaler().fit(X).transform(X)
ols = LinearRegression()
ols.fit(scale_X,Y)
ols_coef = ols.coef_[3]
lamdas = np.linspace(0.01,0.4, 100)
coef_ols = np.repeat(ols_coef,100)
###############################################
lasso_bath_coef = []
lasso_coefs=[]
for a in lamdas:
lasso.set_params(alpha=a,normalize = False)
lasso.fit(scale_X, Y)
lasso_bath_coef.append(lasso.coef_[3])
lasso_coefs.append(lasso.coef_)
#################################################
ridge_bath_coef = []
for a in lamdas:
ridge = Ridge(alpha=a,normalize = True)
ridge.fit(scale_X, Y)
ridge_bath_coef.append(ridge.coef_[3])
####################################################
poslasso_coef = [ ]
for a in range(100):
scale_X = StandardScaler().fit(X.iloc[:, (lasso_coefs[a] != 0)]).transform(X.iloc[:, (lasso_coefs[a] != 0)])
ols = LinearRegression()
ols.fit(scale_X,Y)
post_coef = ols.coef_[X.iloc[:, (lasso_coefs[a] != 0)].columns.get_loc('BATHS')]
poslasso_coef.append(post_coef )
#################################################
plt.figure(figsize=(18,5))
plt.plot(lamdas, ridge_bath_coef, label = 'Ridge', color = 'g', marker='+', linestyle = ':',markevery=8)
plt.plot(lamdas, lasso_bath_coef, label = 'Lasso', color = 'r', marker = '^',linestyle = 'dashed',markevery=8)
plt.plot(lamdas, coef_ols, label = 'OLS', color = 'b',marker = 'x',linestyle = 'dashed',markevery=8)
plt.plot(lamdas, poslasso_coef, label = 'postlasso',color='black',marker = 'o',linestyle = 'dashed',markevery=8 )
plt.legend()
plt.title("Coefficient estimate on Baths")
plt.ylabel('Coef')
plt.xlabel('lambda')
Text(0.5, 0, 'lambda')
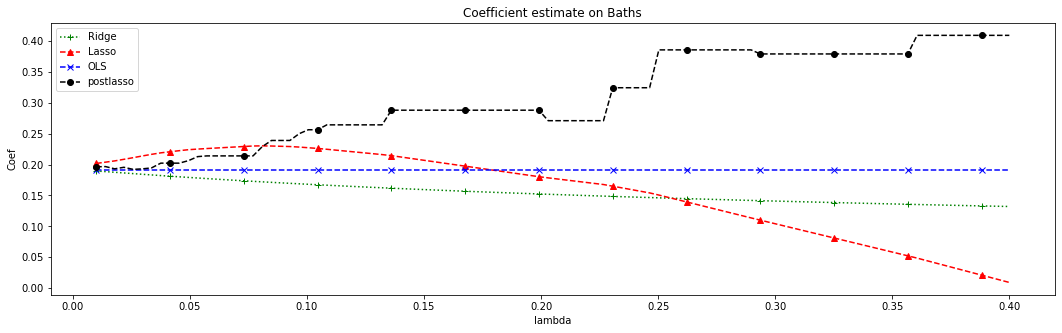
The OLS coefficients are not penalized, so they remain constant. Ridge estimates decrease monotonically as \(\lambda\) grows. Also, for this dataset, Lasso estimates first increase and then decrease. Meanwhile, the post-lasso coefficient estimates seem to behave somewhat erratically with \(lambda\). To understand this behavior, let’s see what happens to the magnitude of other selected variables that are correlated with BATHS.
scale_X = StandardScaler().fit(X).transform(X)
UNITSF_coef = []
BEDRMS_coef = []
DINING_coef = []
for a in lamdas:
lasso.set_params(alpha=a,normalize = False)
lasso.fit(scale_X, Y)
UNITSF_coef.append(lasso.coef_[1])
BEDRMS_coef.append(lasso.coef_[4])
DINING_coef.append(lasso.coef_[5])
plt.figure(figsize=(18,5))
plt.plot(lamdas, UNITSF_coef,label = 'UNITSF', color = 'black' )
plt.plot(lamdas, BEDRMS_coef,label = 'BEDRMS', color = 'red', linestyle = '--')
plt.plot(lamdas, DINING_coef,label = 'DINING', color = 'g',linestyle = 'dotted')
plt.legend()
plt.ylabel('Coef')
plt.xlabel('lambda')
Text(0.5, 0, 'lambda')
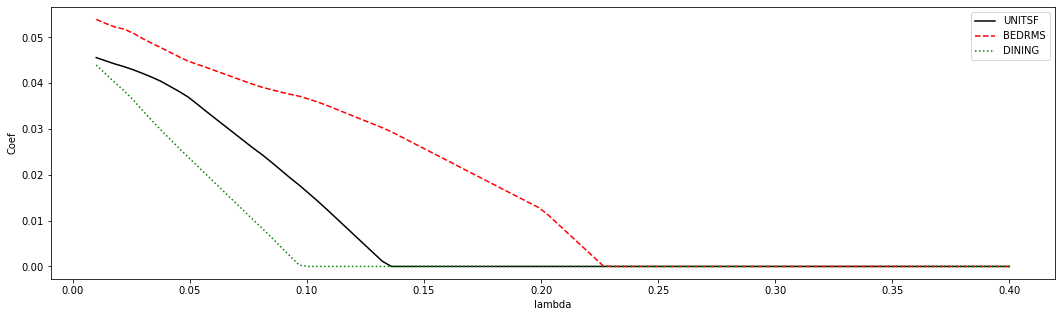
Note how the discrete jumps in magnitude for the BATHS coefficient in the first coincide with, for example, variables DINING and BEDRMS being exactly zero. As these variables got dropped from the model, the coefficient on BATHS increased to pick up their effect.
Another problem with Lasso coefficients is their instability. When multiple variables are highly correlated we may spuriously drop several of them. To get a sense of the amount of variability, in the next snippet we fix \(\lambda\) and then look at the lasso coefficients estimated during cross-validation. We see that by simply removing one fold we can get a very different set of coefficients (nonzero coefficients are in black in the heatmap below). This is because there may be many choices of coefficients with similar predictive power, so the set of nonzero coefficients we end up with can be quite unstable.
import itertools
nobs = X.shape[0]
nfold = 10
# Define folds indices
list_1 = [*range(0, nfold, 1)]*nobs
sample = np.random.choice(nobs,nobs, replace=False).tolist()
foldid = [list_1[index] for index in sample]
# Create split function(similar to R)
def split(x, f):
count = max(f) + 1
return tuple( list(itertools.compress(x, (el == i for el in f))) for i in range(count) )
# Split observation indices into folds
list_2 = [*range(0, nobs, 1)]
I = split(list_2, foldid)
from sklearn.linear_model import LassoCV
scale_X = StandardScaler().fit(X).transform(X)
lasso_coef_fold=[]
for b in range(0,len(I)):
# Split data - index to keep are in mask as booleans
include_idx = set(I[b]) #Here should go I[b] Set is more efficient, but doesn't reorder your elements if that is desireable
mask = np.array([(i in include_idx) for i in range(len(X))])
# Lasso regression, excluding folds selected
lassocv = LassoCV(random_state=0)
lassocv.fit(scale_X[~mask], Y[~mask])
lasso_coef_fold.append(lassocv.coef_)
index_val = ['Fold-1','Fold-2','Fold-3','Fold-4','Fold-5','Fold-6','Fold-7','Fold-8','Fold-9','Fold-10']
df = pd.DataFrame(data= lasso_coef_fold, columns=X.columns, index = index_val).T
df.style.applymap(lambda x: "background-color: white" if x==0 else "background-color: black")
| Fold-1 | Fold-2 | Fold-3 | Fold-4 | Fold-5 | Fold-6 | Fold-7 | Fold-8 | Fold-9 | Fold-10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| LOT | 0.041050 | 0.040789 | 0.039105 | 0.037300 | 0.041148 | 0.043150 | 0.037104 | 0.035392 | 0.037300 | 0.037464 |
| UNITSF | 0.044746 | 0.046055 | 0.047095 | 0.045291 | 0.049540 | 0.043839 | 0.043077 | 0.051535 | 0.047132 | 0.046415 |
| BUILT | 0.001111 | 0.004845 | 0.003385 | 0.003564 | 0.004757 | 0.003220 | 0.003449 | 0.002987 | 0.000929 | 0.004401 |
| BATHS | 0.200578 | 0.189623 | 0.195828 | 0.200489 | 0.192490 | 0.198082 | 0.203624 | 0.200081 | 0.198007 | 0.198827 |
| BEDRMS | 0.055605 | 0.057472 | 0.055982 | 0.055394 | 0.054981 | 0.056335 | 0.054475 | 0.049082 | 0.055994 | 0.052763 |
| DINING | 0.047736 | 0.046748 | 0.047269 | 0.044850 | 0.044751 | 0.046515 | 0.044934 | 0.048129 | 0.046415 | 0.046481 |
| METRO | 0.000000 | 0.000356 | 0.000000 | 0.001081 | 0.001190 | 0.000881 | 0.000000 | 0.003189 | 0.001222 | 0.002415 |
| CRACKS | 0.020332 | 0.020937 | 0.017848 | 0.015932 | 0.019917 | 0.019677 | 0.018395 | 0.023793 | 0.020314 | 0.019614 |
| REGION | 0.083864 | 0.083337 | 0.080464 | 0.081884 | 0.081064 | 0.082150 | 0.078420 | 0.082237 | 0.082466 | 0.082625 |
| METRO3 | 0.007152 | 0.006738 | 0.009395 | 0.009017 | 0.010476 | 0.010692 | 0.007217 | 0.008143 | 0.008373 | 0.007819 |
| PHONE | 0.003223 | 0.004145 | 0.000000 | 0.000000 | 0.003644 | 0.001984 | 0.001331 | 0.003200 | 0.001796 | 0.001127 |
| KITCHEN | -0.003205 | -0.000000 | -0.000955 | -0.002583 | -0.007191 | -0.002836 | -0.000000 | -0.003221 | -0.005402 | -0.000577 |
| MOBILTYP | -0.119085 | -0.103709 | -0.118946 | -0.111606 | -0.106277 | -0.113575 | -0.109086 | -0.103446 | -0.114251 | -0.115418 |
| WINTEROVEN | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| WINTERKESP | 0.000000 | -0.000000 | 0.000000 | 0.000000 | -0.000000 | 0.000000 | 0.000000 | -0.000000 | 0.000000 | 0.000000 |
| WINTERELSP | 0.026793 | 0.021703 | 0.025619 | 0.026638 | 0.026866 | 0.024999 | 0.024933 | 0.030121 | 0.026697 | 0.027365 |
| WINTERWOOD | 0.000000 | -0.000000 | 0.000000 | 0.000000 | -0.000000 | 0.000000 | 0.000000 | -0.000000 | 0.000000 | 0.000000 |
| WINTERNONE | -0.006475 | -0.007696 | -0.001862 | -0.000594 | -0.003744 | -0.001674 | -0.002170 | -0.004903 | -0.008437 | -0.001137 |
| NEWC | 0.029223 | 0.027175 | 0.027914 | 0.026626 | 0.027992 | 0.029549 | 0.031211 | 0.027483 | 0.028221 | 0.028651 |
| DISH | -0.096273 | -0.098615 | -0.095563 | -0.093536 | -0.095071 | -0.097641 | -0.094371 | -0.098233 | -0.095227 | -0.096898 |
| WASH | -0.001606 | -0.008013 | -0.012339 | -0.002369 | -0.016570 | -0.002033 | -0.011885 | -0.004852 | -0.007794 | -0.010408 |
| DRY | -0.034784 | -0.032210 | -0.029772 | -0.031367 | -0.027754 | -0.035728 | -0.029114 | -0.029364 | -0.032434 | -0.026725 |
| NUNIT2 | -0.216673 | -0.229393 | -0.213668 | -0.219420 | -0.230576 | -0.219189 | -0.224386 | -0.228164 | -0.217753 | -0.218393 |
| BURNER | -0.000000 | -0.000000 | 0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | 0.000000 | 0.000000 | 0.000000 |
| COOK | -0.000000 | -0.000000 | 0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | 0.000000 | 0.000000 | 0.000000 |
| OVEN | -0.000000 | -0.000000 | 0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | 0.000000 | 0.000000 | 0.000000 |
| REFR | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 |
| DENS | 0.048246 | 0.049359 | 0.046588 | 0.047767 | 0.051190 | 0.046928 | 0.046455 | 0.047423 | 0.049179 | 0.048865 |
| FAMRM | 0.057822 | 0.057013 | 0.057238 | 0.059208 | 0.058518 | 0.055123 | 0.057817 | 0.058604 | 0.059895 | 0.057424 |
| HALFB | 0.103928 | 0.102791 | 0.105183 | 0.104379 | 0.103671 | 0.106806 | 0.112708 | 0.104332 | 0.104481 | 0.108234 |
| KITCH | -0.016848 | -0.015641 | -0.015128 | -0.014620 | -0.015921 | -0.015672 | -0.016561 | -0.013676 | -0.016945 | -0.017092 |
| LIVING | 0.005198 | 0.002324 | 0.003951 | 0.004839 | 0.006106 | 0.005630 | 0.003494 | 0.003993 | 0.004532 | 0.004339 |
| OTHFN | 0.038355 | 0.036114 | 0.039843 | 0.035012 | 0.038077 | 0.037492 | 0.034321 | 0.037525 | 0.037721 | 0.035186 |
| RECRM | 0.021484 | 0.021937 | 0.019965 | 0.023502 | 0.024159 | 0.020679 | 0.019380 | 0.020446 | 0.022242 | 0.020969 |
| CLIMB | 0.012317 | 0.006384 | 0.011059 | 0.011721 | 0.016332 | 0.016591 | 0.011285 | 0.013526 | 0.013106 | 0.010781 |
| ELEV | 0.076095 | 0.083937 | 0.078783 | 0.079432 | 0.089403 | 0.078455 | 0.084076 | 0.083452 | 0.082064 | 0.078135 |
| DIRAC | -0.003499 | -0.003454 | -0.002993 | -0.004058 | -0.003754 | -0.002351 | -0.001929 | -0.002463 | -0.001677 | -0.001690 |
| PORCH | -0.018848 | -0.015829 | -0.016723 | -0.014969 | -0.013677 | -0.014311 | -0.015005 | -0.015080 | -0.016535 | -0.013887 |
| AIRSYS | -0.049124 | -0.052072 | -0.052840 | -0.053260 | -0.051097 | -0.050265 | -0.053449 | -0.053212 | -0.052109 | -0.051032 |
| WELL | -0.000000 | 0.000000 | -0.000000 | 0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 |
| WELDUS | -0.024269 | -0.024428 | -0.025118 | -0.022449 | -0.024388 | -0.023465 | -0.022414 | -0.023391 | -0.023995 | -0.026031 |
| STEAM | 0.002214 | 0.003292 | 0.000000 | 0.000000 | 0.002270 | 0.002277 | 0.000000 | 0.004752 | 0.002812 | 0.000000 |
| OARSYS | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| noise1 | 0.005424 | 0.002849 | 0.006610 | 0.003614 | 0.006709 | 0.003801 | 0.002519 | 0.005297 | 0.002566 | 0.005736 |
| noise2 | 0.000000 | -0.000000 | -0.000000 | -0.000000 | 0.000000 | 0.000000 | -0.000000 | 0.000000 | 0.000000 | -0.000000 |
| noise3 | 0.000000 | -0.000000 | -0.000000 | 0.000000 | 0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 |
| noise4 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.001688 | 0.000000 | 0.003442 | 0.000000 | 0.000000 |
| noise5 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000172 |
| noise6 | -0.000805 | -0.001709 | -0.002072 | -0.004038 | -0.001111 | -0.003315 | -0.000000 | -0.004309 | -0.002370 | -0.000000 |
| noise7 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | 0.000000 | 0.000000 | -0.000000 | -0.000000 | -0.000000 | 0.000000 |
| noise8 | 0.003441 | 0.009192 | 0.004116 | 0.002452 | 0.006297 | 0.004724 | 0.005267 | 0.003611 | 0.005380 | 0.002053 |
| noise9 | -0.000000 | 0.000000 | -0.000000 | -0.000000 | -0.000258 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 |
| noise10 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000021 | -0.000000 |
| noise11 | -0.008055 | -0.004641 | -0.005265 | -0.002612 | -0.007669 | -0.005447 | -0.007216 | -0.006012 | -0.007707 | -0.003743 |
| noise12 | -0.006468 | -0.007073 | -0.003561 | -0.002931 | -0.006589 | -0.003944 | -0.005517 | -0.002839 | -0.007282 | -0.005623 |
| noise13 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000212 | 0.000000 | 0.000000 | 0.000000 | 0.002019 | 0.000000 |
| noise14 | -0.000124 | -0.000000 | 0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | 0.000000 | -0.000000 | 0.000000 |
| noise15 | 0.002332 | 0.004505 | 0.004589 | 0.002373 | 0.004535 | 0.003080 | 0.001490 | 0.004166 | 0.004509 | 0.002482 |
| noise16 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -0.000000 | 0.000000 | 0.000000 | 0.000000 |
| noise17 | -0.002321 | -0.001854 | -0.003085 | -0.001049 | -0.004635 | -0.000000 | -0.000465 | -0.001222 | -0.002072 | -0.002135 |
| noise18 | 0.000274 | 0.000000 | 0.000000 | 0.000704 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.001272 | 0.000000 |
| noise19 | 0.000000 | 0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | 0.000000 | -0.000000 | -0.000000 | 0.000000 |
| noise20 | -0.000904 | -0.002203 | -0.001322 | -0.000250 | -0.000000 | -0.000180 | -0.001053 | -0.001291 | -0.005082 | -0.000000 |
| ranking | -0.002614 | -0.003632 | -0.000309 | -0.001322 | -0.002222 | -0.000030 | -0.001472 | -0.002578 | -0.000000 | -0.000000 |
As we have seen above, any interpretation needs to take into account the joint distribution of covariates. One possible heuristic is to consider data-driven subgroups. For example, we can analyze what differentiates observations whose predictions are high from those whose predictions are low. The following code estimates a flexible Lasso model with splines, ranks the observations into a few subgroups according to their predicted outcomes, and then estimates the average covariate value for each subgroup.
import itertools
nobs = X.shape[0]
nfold = 5
# Define folds indices
list_1 = [*range(0, nfold, 1)]*nobs
sample = np.random.choice(nobs,nobs, replace=False).tolist()
foldid = [list_1[index] for index in sample]
# Create split function(similar to R)
def split(x, f):
count = max(f) + 1
return tuple( list(itertools.compress(x, (el == i for el in f))) for i in range(count) )
# Split observation indices into folds
list_2 = [*range(0, nobs, 1)]
I = split(list_2, foldid)
lasso_coef_rank=[]
lasso_pred = []
for b in range(0,len(I)):
# Split data - index to keep are in mask as booleans
include_idx = set(I[b]) #Here should go I[b] Set is more efficient, but doesn't reorder your elements if that is desireable
mask = np.array([(i in include_idx) for i in range(len(X))])
# Lasso regression, excluding folds selected
lassocv = LassoCV(random_state=0)
lassocv.fit(scale_X[~mask], Y[~mask])
lasso_coef_rank.append(lassocv.coef_)
lasso_pred.append(lassocv.predict(scale_X[mask]))
y_hat = lasso_pred
df_1 = pd.DataFrame()
for i in [0,1,2,3,4]:
df_2 = pd.DataFrame(y_hat[i])
b =pd.cut(df_2[0], bins =[np.percentile(df_2,0),np.percentile(df_2,25),np.percentile(df_2,50),
np.percentile(df_2,75),np.percentile(df_2,100)], labels = [1,2,3,4])
df_1 = pd.concat([df_1, b])
df_1 =df_1.apply(lambda x: pd.factorize(x)[0])
df_1.rename(columns={0:'ranking'}, inplace=True)
df_1 =df_1.reset_index().drop(columns=['index'])
import statsmodels.api as sm
from scipy.stats import norm
import statsmodels.formula.api as smf
y = X
x = df_1
y = pd.DataFrame(y)
x = pd.DataFrame(x)
y['ranking'] = x
data = y
data_frame = pd.DataFrame()
for var_name in covariates:
form = var_name + " ~ " + "0" + "+" + "C(ranking)"
df1 = smf.ols(formula=form, data=data).fit(cov_type = 'HC2').summary2().tables[1].iloc[1:5, :2] #iloc to stay with rankings 0,1,2,3
df1.insert(0, 'covariate', var_name)
df1.insert(3, 'ranking', ['G1','G2','G3','G4'])
df1.insert(4, 'scaling',
pd.DataFrame(norm.cdf((df1['Coef.'] - np.mean(df1['Coef.']))/np.std(df1['Coef.']))))
df1.insert(5, 'variation',
np.std(df1['Coef.'])/np.std(data[var_name]))
label = []
for j in range(0,4):
label += [str(round(df1['Coef.'][j],3)) + " ("
+ str(round(df1['Std.Err.'][j],3)) + ")"]
df1.insert(6, 'labels', label)
df1.reset_index().drop(columns=['index'])
index = []
for m in range(0,4):
index += [str(df1['covariate'][m]) + "_" + "ranking" + str(m+1)]
idx = pd.Index(index)
df1 = df1.set_index(idx)
data_frame = data_frame.append(df1)
data_frame;
labels_data = pd.DataFrame()
for i in range(1,5):
df_mask = data_frame['ranking']==f"G{i}"
filtered_df = data_frame[df_mask].reset_index().drop(columns=['index'])
labels_data[f"ranking{i}"] = filtered_df[['labels']]
labels_data = labels_data.set_index(pd.Index(covariates))
labels_data
| ranking1 | ranking2 | ranking3 | ranking4 | |
|---|---|---|---|---|
| LOT | 49713.31 (1473.048) | 46479.968 (1390.394) | 47806.63 (1427.658) | 47612.513 (1393.569) |
| UNITSF | 2415.869 (24.944) | 2434.834 (24.249) | 2397.706 (23.467) | 2471.907 (26.208) |
| BUILT | 1972.286 (0.301) | 1974.925 (0.294) | 1973.672 (0.299) | 1973.017 (0.299) |
| BATHS | 1.918 (0.009) | 1.975 (0.009) | 1.946 (0.009) | 1.928 (0.009) |
| BEDRMS | 3.218 (0.01) | 3.258 (0.01) | 3.251 (0.01) | 3.243 (0.01) |
| ... | ... | ... | ... | ... |
| noise16 | 0.499 (0.003) | 0.502 (0.003) | 0.498 (0.003) | 0.505 (0.003) |
| noise17 | 0.501 (0.003) | 0.498 (0.003) | 0.502 (0.003) | 0.498 (0.003) |
| noise18 | 0.502 (0.003) | 0.499 (0.003) | 0.5 (0.003) | 0.5 (0.003) |
| noise19 | 0.504 (0.003) | 0.502 (0.003) | 0.498 (0.003) | 0.497 (0.003) |
| noise20 | 0.502 (0.003) | 0.496 (0.003) | 0.501 (0.003) | 0.5 (0.003) |
63 rows × 4 columns
The next heatmap visualizes the results. Note how observations ranked higher (i.e., were predicted to have higher prices) have more bedrooms and baths, were built more recently, have fewer cracks, and so on. The next snippet of code displays the average covariate per group along with each standard errors. The rows are ordered according to \(Var(E[X_{ij} | G_i) / Var(X_i)\), where \(G_i\) denotes the ranking. This is a rough normalized measure of how much variation is “explained” by group membership \(G_i\). Brighter colors indicate larger values.
new_data = pd.DataFrame()
for i in range(0,4):
df_mask = data_frame['ranking']==f"G{i+1}"
filtered_df = data_frame[df_mask]
new_data.insert(i,f"G{i+1}",filtered_df[['scaling']])
new_data;
features = covariates
ranks = ['G1','G2','G3','G4']
harvest = np.array(round(new_data,3))
labels_hm = np.array(round(labels_data))
fig, ax = plt.subplots(figsize=(10,15))
# getting the original colormap using cm.get_cmap() function
orig_map = plt.cm.get_cmap('copper')
# reversing the original colormap using reversed() function
reversed_map = orig_map.reversed()
im = ax.imshow(harvest, cmap=reversed_map, aspect='auto')
# make bar
bar = plt.colorbar(im, shrink=0.2)
# show plot with labels
bar.set_label('scaling')
# Setting the labels
ax.set_xticks(np.arange(len(ranks)))
ax.set_yticks(np.arange(len(features)))
# labeling respective list entries
ax.set_xticklabels(ranks)
ax.set_yticklabels(features)
# Rotate the tick labels and set their alignment.
plt.setp(ax.get_xticklabels(), ha="right",
rotation_mode="anchor")
# Creating text annotations by using for loop
for i in range(len(features)):
for j in range(len(ranks)):
text = ax.text(j, i, labels_hm[i, j],
ha="center", va="center", color="w")
ax.set_title("Average covariate values within group (based on prediction ranking)")
fig.tight_layout()
plt.show()

As we just saw above, houses that have, e.g., been built more recently (BUILT), have more baths (BATHS) are associated with larger price predictions.
This sort of interpretation exercise did not rely on reading any coefficients, and in fact it could also be done using any other flexible method, including decisions trees and forests.
2.2.2. Decision Tree#
This next class of algorithms divides the covariate space into “regions” and estimates a constant prediction within each region.
To estimate a decision tree, we following a recursive partition algorithm. At each stage, we select one variable \(j\) and one split point \(s\), and divide the observations into “left” and “right” subsets, depending on whether \(X_{ij} \leq s\) or \(X_{ij} > s\). For regression problems, the variable and split points are often selected so that the sum of the variances of the outcome variable in each “child” subset is smallest. For classification problems, we split to separate the classes. Then, for each child, we separately repeat the process of finding variables and split points. This continues until a minimum subset size is reached, or improvement falls below some threshold.
At prediction time, to find the predictions for some point \(x\), we just follow the tree we just built, going left or right according to the selected variables and split points, until we reach a terminal node. Then, for regression problems, the predicted value at some point \(x\) is the average outcome of the observations in the same partition as the point \(x\). For classification problems, we output the majority class in the node.
from sklearn.tree import DecisionTreeRegressor
import graphviz
from sklearn import tree
from sklearn.tree import export_graphviz
from sklearn.metrics import accuracy_score
from pandas import Series
from simple_colors import *
import statsmodels.api as sm
import statsmodels.formula.api as smf
from scipy.stats import norm
from sklearn.metrics import accuracy_score
from sklearn import metrics
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
from sklearn import tree
from sklearn.model_selection import train_test_split
#Here we define our X and Y variable
Y = data.loc[:,outcome]
XX = data.loc[:,covariates]
# we split data in train and test
x_train, x_test, y_train, y_test = train_test_split(XX.to_numpy(), Y, test_size=.3)
dt = DecisionTreeRegressor( max_depth=15, random_state=0)
#x_train, x_test, y_train, y_test = train_test_split(XX.to_numpy(), Y, test_size=.3)
tree1 = dt.fit(x_train,y_train)
At this point, we have not constrained the complexity of the tree in any way, so it’s likely too deep and probably overfits. Here’s a plot of what we have so far (without bothering to label the splits to avoid clutter).
from sklearn import tree
plt.figure(figsize=(18,5))
tree.plot_tree(dt)
[Text(0.6937715956946345, 0.96875, 'X[12] <= 0.0\nsquared_error = 0.981\nsamples = 20108\nvalue = 11.814'),
Text(0.45393733459285945, 0.90625, 'X[1] <= 2436.5\nsquared_error = 0.774\nsamples = 19386\nvalue = 11.889'),
Text(0.23878549020890355, 0.84375, 'X[3] <= 1.5\nsquared_error = 0.631\nsamples = 13895\nvalue = 11.687'),
Text(0.11155233658026083, 0.78125, 'X[19] <= 1.5\nsquared_error = 0.705\nsamples = 5094\nvalue = 11.392'),
Text(0.05217431774271454, 0.71875, 'X[29] <= 0.5\nsquared_error = 0.677\nsamples = 2626\nvalue = 11.544'),
Text(0.02204757687972951, 0.65625, 'X[14] <= -3.0\nsquared_error = 0.82\nsamples = 1133\nvalue = 11.421'),
Text(0.0019320560296248591, 0.59375, 'X[47] <= 0.904\nsquared_error = 15.873\nsamples = 7\nvalue = 9.561'),
Text(0.0016100466913540493, 0.53125, 'X[30] <= 1.5\nsquared_error = 0.743\nsamples = 6\nvalue = 11.155'),
Text(0.0012880373530832394, 0.46875, 'X[44] <= 0.392\nsquared_error = 0.256\nsamples = 5\nvalue = 10.829'),
Text(0.0006440186765416197, 0.40625, 'X[1] <= 1536.402\nsquared_error = 0.012\nsamples = 2\nvalue = 10.234'),
Text(0.00032200933827080985, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.342'),
Text(0.0009660280148124296, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.127'),
Text(0.0019320560296248591, 0.40625, 'X[57] <= 0.52\nsquared_error = 0.027\nsamples = 3\nvalue = 11.226'),
Text(0.0016100466913540493, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.002'),
Text(0.0022540653678956688, 0.34375, 'X[58] <= 0.333\nsquared_error = 0.002\nsamples = 2\nvalue = 11.337'),
Text(0.0019320560296248591, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.385'),
Text(0.002576074706166479, 0.28125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.29'),
Text(0.0019320560296248591, 0.46875, 'squared_error = 0.0\nsamples = 1\nvalue = 12.782'),
Text(0.0022540653678956688, 0.53125, 'squared_error = -0.0\nsamples = 1\nvalue = 0.0'),
Text(0.04216309772983416, 0.59375, 'X[1] <= 2431.402\nsquared_error = 0.705\nsamples = 1126\nvalue = 11.432'),
Text(0.021499154725487038, 0.53125, 'X[15] <= 1.5\nsquared_error = 0.461\nsamples = 976\nvalue = 11.488'),
Text(0.00612824021896635, 0.46875, 'X[49] <= 0.024\nsquared_error = 1.171\nsamples = 184\nvalue = 11.304'),
Text(0.0038641120592497183, 0.40625, 'X[1] <= 1495.0\nsquared_error = 21.608\nsamples = 5\nvalue = 9.292'),
Text(0.003542102720978908, 0.34375, 'X[1] <= 750.0\nsquared_error = 0.028\nsamples = 4\nvalue = 11.615'),
Text(0.0032200933827080985, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.35'),
Text(0.0038641120592497183, 0.28125, 'X[49] <= 0.003\nsquared_error = 0.006\nsamples = 3\nvalue = 11.703'),
Text(0.003542102720978908, 0.21875, 'X[38] <= 1.5\nsquared_error = 0.0\nsamples = 2\nvalue = 11.756'),
Text(0.0032200933827080985, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.775'),
Text(0.0038641120592497183, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.736'),
Text(0.004186121397520528, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.599'),
Text(0.004186121397520528, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 0.0'),
Text(0.008392368378682982, 0.40625, 'X[50] <= 0.067\nsquared_error = 0.484\nsamples = 179\nvalue = 11.361'),
Text(0.0056351634197391726, 0.34375, 'X[48] <= 0.202\nsquared_error = 4.939\nsamples = 7\nvalue = 10.455'),
Text(0.005313154081468363, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 5.075'),
Text(0.005957172758009982, 0.28125, 'X[61] <= 0.559\nsquared_error = 0.136\nsamples = 6\nvalue = 11.351'),
Text(0.005152149412332958, 0.21875, 'X[2] <= 1945.0\nsquared_error = 0.049\nsamples = 4\nvalue = 11.559'),
Text(0.0045081307357913375, 0.15625, 'X[55] <= 0.564\nsquared_error = 0.019\nsamples = 2\nvalue = 11.364'),
Text(0.004186121397520528, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.503'),
Text(0.004830140074062148, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 11.225'),
Text(0.005796168088874577, 0.15625, 'X[6] <= 4.0\nsquared_error = 0.003\nsamples = 2\nvalue = 11.754'),
Text(0.005474158750603767, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.695'),
Text(0.0061181774271453875, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 11.813'),
Text(0.006762196103687007, 0.21875, 'X[50] <= 0.045\nsquared_error = 0.049\nsamples = 2\nvalue = 10.935'),
Text(0.006440186765416197, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.156'),
Text(0.007084205441957816, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.714'),
Text(0.01114957333762679, 0.34375, 'X[1] <= 775.0\nsquared_error = 0.268\nsamples = 172\nvalue = 11.397'),
Text(0.008211238125905651, 0.28125, 'X[46] <= 0.405\nsquared_error = 0.917\nsamples = 7\nvalue = 10.553'),
Text(0.007889228787634841, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 8.412'),
Text(0.008533247464176462, 0.21875, 'X[50] <= 0.602\nsquared_error = 0.178\nsamples = 6\nvalue = 10.91'),
Text(0.0077282241184994365, 0.15625, 'X[49] <= 0.622\nsquared_error = 0.055\nsamples = 2\nvalue = 10.362'),
Text(0.007406214780228627, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.597'),
Text(0.008050233456770247, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 10.127'),
Text(0.009338270809853486, 0.15625, 'X[0] <= 6500.0\nsquared_error = 0.014\nsamples = 4\nvalue = 11.184'),
Text(0.008694252133311866, 0.09375, 'X[46] <= 0.652\nsquared_error = 0.006\nsamples = 2\nvalue = 11.079'),
Text(0.008372242795041056, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.002'),
Text(0.009016261471582675, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.156'),
Text(0.009982289486395105, 0.09375, 'X[24] <= 1.5\nsquared_error = 0.0\nsamples = 2\nvalue = 11.29'),
Text(0.009660280148124296, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.29'),
Text(0.010304298824665915, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.29'),
Text(0.014087908549347931, 0.28125, 'X[57] <= 0.867\nsquared_error = 0.208\nsamples = 165\nvalue = 11.433'),
Text(0.01175334084688456, 0.21875, 'X[52] <= 0.013\nsquared_error = 0.195\nsamples = 140\nvalue = 11.481'),
Text(0.010948317501207535, 0.15625, 'X[47] <= 0.342\nsquared_error = 0.12\nsamples = 2\nvalue = 10.473'),
Text(0.010626308162936726, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.82'),
Text(0.011270326839478345, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.127'),
Text(0.012558364192561584, 0.15625, 'X[1] <= 912.5\nsquared_error = 0.181\nsamples = 138\nvalue = 11.496'),
Text(0.011914345516019964, 0.09375, 'X[60] <= 0.831\nsquared_error = 0.122\nsamples = 14\nvalue = 11.195'),
Text(0.011592336177749154, 0.03125, 'squared_error = 0.064\nsamples = 12\nvalue = 11.301'),
Text(0.012236354854290775, 0.03125, 'squared_error = 0.002\nsamples = 2\nvalue = 10.558'),
Text(0.013202382869103205, 0.09375, 'X[8] <= 3.5\nsquared_error = 0.176\nsamples = 124\nvalue = 11.53'),
Text(0.012880373530832394, 0.03125, 'squared_error = 0.161\nsamples = 114\nvalue = 11.495'),
Text(0.013524392207374013, 0.03125, 'squared_error = 0.174\nsamples = 10\nvalue = 11.932'),
Text(0.016422476251811303, 0.21875, 'X[62] <= 0.43\nsquared_error = 0.198\nsamples = 25\nvalue = 11.165'),
Text(0.015134438898728063, 0.15625, 'X[43] <= 0.366\nsquared_error = 0.2\nsamples = 10\nvalue = 11.448'),
Text(0.014490420222186443, 0.09375, 'X[52] <= 0.181\nsquared_error = 0.253\nsamples = 4\nvalue = 11.084'),
Text(0.014168410883915633, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.918'),
Text(0.014812429560457254, 0.03125, 'squared_error = 0.027\nsamples = 3\nvalue = 10.806'),
Text(0.015778457575269682, 0.09375, 'X[48] <= 0.25\nsquared_error = 0.019\nsamples = 6\nvalue = 11.69'),
Text(0.015456448236998873, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 11.513'),
Text(0.016100466913540494, 0.03125, 'squared_error = 0.005\nsamples = 4\nvalue = 11.779'),
Text(0.01771051360489454, 0.15625, 'X[60] <= 0.278\nsquared_error = 0.108\nsamples = 15\nvalue = 10.976'),
Text(0.017066494928352924, 0.09375, 'X[0] <= 25034.602\nsquared_error = 0.027\nsamples = 3\nvalue = 10.514'),
Text(0.01674448559008211, 0.03125, 'squared_error = 0.01\nsamples = 2\nvalue = 10.617'),
Text(0.017388504266623733, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.309'),
Text(0.018354532281436162, 0.09375, 'X[47] <= 0.262\nsquared_error = 0.062\nsamples = 12\nvalue = 11.091'),
Text(0.01803252294316535, 0.03125, 'squared_error = 0.011\nsamples = 4\nvalue = 11.388'),
Text(0.01867654161970697, 0.03125, 'squared_error = 0.021\nsamples = 8\nvalue = 10.943'),
Text(0.03687006923200773, 0.46875, 'X[34] <= 2.154\nsquared_error = 0.286\nsamples = 792\nvalue = 11.53'),
Text(0.02849782643696667, 0.40625, 'X[47] <= 0.991\nsquared_error = 0.347\nsamples = 81\nvalue = 11.265'),
Text(0.028175817098695863, 0.34375, 'X[46] <= 0.888\nsquared_error = 0.282\nsamples = 80\nvalue = 11.295'),
Text(0.024150700370310738, 0.28125, 'X[46] <= 0.465\nsquared_error = 0.247\nsamples = 69\nvalue = 11.216'),
Text(0.02157462566414426, 0.21875, 'X[60] <= 0.197\nsquared_error = 0.203\nsamples = 43\nvalue = 11.374'),
Text(0.020286588311061022, 0.15625, 'X[8] <= 3.5\nsquared_error = 0.137\nsamples = 6\nvalue = 10.849'),
Text(0.0196425696345194, 0.09375, 'X[51] <= 0.46\nsquared_error = 0.013\nsamples = 3\nvalue = 11.196'),
Text(0.019320560296248592, 0.03125, 'squared_error = 0.001\nsamples = 2\nvalue = 11.119'),
Text(0.01996457897279021, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.35'),
Text(0.02093060698760264, 0.09375, 'X[4] <= 1.5\nsquared_error = 0.018\nsamples = 3\nvalue = 10.501'),
Text(0.02060859764933183, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.309'),
Text(0.02125261632587345, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 10.597'),
Text(0.0228626630172275, 0.15625, 'X[47] <= 0.935\nsquared_error = 0.162\nsamples = 37\nvalue = 11.459'),
Text(0.02221864434068588, 0.09375, 'X[44] <= 0.052\nsquared_error = 0.126\nsamples = 35\nvalue = 11.506'),
Text(0.02189663500241507, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.463'),
Text(0.02254065367895669, 0.03125, 'squared_error = 0.097\nsamples = 34\nvalue = 11.537'),
Text(0.02350668169376912, 0.09375, 'X[34] <= 0.5\nsquared_error = 0.055\nsamples = 2\nvalue = 10.624'),
Text(0.023184672355498308, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.859'),
Text(0.02382869103203993, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.389'),
Text(0.026726775076477218, 0.21875, 'X[48] <= 0.556\nsquared_error = 0.211\nsamples = 26\nvalue = 10.956'),
Text(0.02543873772339398, 0.15625, 'X[51] <= 0.711\nsquared_error = 0.184\nsamples = 16\nvalue = 10.775'),
Text(0.02479471904685236, 0.09375, 'X[56] <= 0.506\nsquared_error = 0.144\nsamples = 13\nvalue = 10.653'),
Text(0.02447270970858155, 0.03125, 'squared_error = 0.09\nsamples = 6\nvalue = 10.381'),
Text(0.025116728385123167, 0.03125, 'squared_error = 0.074\nsamples = 7\nvalue = 10.886'),
Text(0.026082756399935597, 0.09375, 'X[62] <= 0.298\nsquared_error = 0.012\nsamples = 3\nvalue = 11.305'),
Text(0.02576074706166479, 0.03125, 'squared_error = 0.001\nsamples = 2\nvalue = 11.379'),
Text(0.02640476573820641, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.156'),
Text(0.028014812429560457, 0.15625, 'X[62] <= 0.479\nsquared_error = 0.118\nsamples = 10\nvalue = 11.245'),
Text(0.02737079375301884, 0.09375, 'X[54] <= 0.347\nsquared_error = 0.045\nsamples = 6\nvalue = 11.44'),
Text(0.027048784414748027, 0.03125, 'squared_error = 0.004\nsamples = 3\nvalue = 11.245'),
Text(0.027692803091289648, 0.03125, 'squared_error = 0.011\nsamples = 3\nvalue = 11.634'),
Text(0.028658831106102078, 0.09375, 'X[41] <= 0.5\nsquared_error = 0.086\nsamples = 4\nvalue = 10.954'),
Text(0.028336821767831265, 0.03125, 'squared_error = 0.027\nsamples = 3\nvalue = 10.806'),
Text(0.028980840444372886, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.396'),
Text(0.03220093382708099, 0.28125, 'X[2] <= 1970.0\nsquared_error = 0.216\nsamples = 11\nvalue = 11.788'),
Text(0.030912896473997746, 0.21875, 'X[54] <= 0.653\nsquared_error = 0.112\nsamples = 6\nvalue = 12.113'),
Text(0.030590887135726937, 0.15625, 'X[1] <= 1050.0\nsquared_error = 0.032\nsamples = 5\nvalue = 12.244'),
Text(0.029946868459185316, 0.09375, 'X[50] <= 0.725\nsquared_error = 0.007\nsamples = 3\nvalue = 12.371'),
Text(0.029624859120914507, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 12.429'),
Text(0.030268877797456125, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 12.255'),
Text(0.031234905812268555, 0.09375, 'X[43] <= 0.796\nsquared_error = 0.01\nsamples = 2\nvalue = 12.053'),
Text(0.030912896473997746, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.155'),
Text(0.031556915150539364, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.951'),
Text(0.031234905812268555, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 11.462'),
Text(0.03348897118016422, 0.21875, 'X[49] <= 0.805\nsquared_error = 0.06\nsamples = 5\nvalue = 11.397'),
Text(0.03316696184189342, 0.15625, 'X[48] <= 0.568\nsquared_error = 0.018\nsamples = 4\nvalue = 11.504'),
Text(0.03252294316535179, 0.09375, 'X[2] <= 1990.0\nsquared_error = 0.004\nsamples = 2\nvalue = 11.628'),
Text(0.03220093382708099, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.562'),
Text(0.032844952503622606, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.695'),
Text(0.033810980518435035, 0.09375, 'X[4] <= 1.5\nsquared_error = 0.001\nsamples = 2\nvalue = 11.379'),
Text(0.03348897118016422, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.35'),
Text(0.03413298985670585, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.408'),
Text(0.033810980518435035, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 10.968'),
Text(0.02881983577523748, 0.34375, 'squared_error = -0.0\nsamples = 1\nvalue = 8.923'),
Text(0.04524231202704879, 0.40625, 'X[8] <= 3.5\nsquared_error = 0.27\nsamples = 711\nvalue = 11.56'),
Text(0.04053292545483819, 0.34375, 'X[42] <= 1.5\nsquared_error = 0.261\nsamples = 642\nvalue = 11.533'),
Text(0.03823860891965867, 0.28125, 'X[62] <= 0.829\nsquared_error = 0.356\nsamples = 113\nvalue = 11.317'),
Text(0.03687006923200773, 0.21875, 'X[2] <= 1919.5\nsquared_error = 0.309\nsamples = 94\nvalue = 11.235'),
Text(0.035743036548059895, 0.15625, 'X[6] <= 4.0\nsquared_error = 0.18\nsamples = 6\nvalue = 10.371'),
Text(0.03509901787151828, 0.09375, 'X[43] <= 0.405\nsquared_error = 0.08\nsamples = 3\nvalue = 10.006'),
Text(0.034777008533247465, 0.03125, 'squared_error = 0.006\nsamples = 2\nvalue = 10.201'),
Text(0.03542102720978908, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 9.616'),
Text(0.03638705522460151, 0.09375, 'X[48] <= 0.894\nsquared_error = 0.014\nsamples = 3\nvalue = 10.737'),
Text(0.0360650458863307, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 10.82'),
Text(0.036709064562872325, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.571'),
Text(0.03799710191595556, 0.15625, 'X[5] <= 1.5\nsquared_error = 0.263\nsamples = 88\nvalue = 11.294'),
Text(0.037675092577684755, 0.09375, 'X[59] <= 0.019\nsquared_error = 0.234\nsamples = 87\nvalue = 11.314'),
Text(0.03735308323941394, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 9.903'),
Text(0.03799710191595556, 0.03125, 'squared_error = 0.213\nsamples = 86\nvalue = 11.33'),
Text(0.03831911125422637, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 9.616'),
Text(0.039607148607309614, 0.21875, 'X[0] <= 269841.5\nsquared_error = 0.389\nsamples = 19\nvalue = 11.722'),
Text(0.0392851392690388, 0.15625, 'X[9] <= 5.5\nsquared_error = 0.161\nsamples = 18\nvalue = 11.607'),
Text(0.03896312993076799, 0.09375, 'X[56] <= 0.846\nsquared_error = 0.112\nsamples = 17\nvalue = 11.55'),
Text(0.038641120592497184, 0.03125, 'squared_error = 0.078\nsamples = 14\nvalue = 11.457'),
Text(0.0392851392690388, 0.03125, 'squared_error = 0.04\nsamples = 3\nvalue = 11.983'),
Text(0.039607148607309614, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.578'),
Text(0.03992915794558042, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 13.786'),
Text(0.04282724199001771, 0.28125, 'X[1] <= 1060.0\nsquared_error = 0.229\nsamples = 529\nvalue = 11.579'),
Text(0.041539204636934474, 0.21875, 'X[52] <= 0.971\nsquared_error = 0.178\nsamples = 162\nvalue = 11.447'),
Text(0.040573176622122044, 0.15625, 'X[56] <= 0.006\nsquared_error = 0.161\nsamples = 159\nvalue = 11.465'),
Text(0.04025116728385123, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 13.017'),
Text(0.04089518596039285, 0.09375, 'X[2] <= 2000.0\nsquared_error = 0.147\nsamples = 158\nvalue = 11.455'),
Text(0.040573176622122044, 0.03125, 'squared_error = 0.132\nsamples = 152\nvalue = 11.43'),
Text(0.04121719529866366, 0.03125, 'squared_error = 0.107\nsamples = 6\nvalue = 12.086'),
Text(0.0425052326517469, 0.15625, 'X[49] <= 0.168\nsquared_error = 0.201\nsamples = 3\nvalue = 10.523'),
Text(0.04218322331347609, 0.09375, 'X[56] <= 0.292\nsquared_error = 0.014\nsamples = 2\nvalue = 10.833'),
Text(0.04186121397520528, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.951'),
Text(0.0425052326517469, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.714'),
Text(0.04282724199001771, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 9.903'),
Text(0.04411527934310095, 0.21875, 'X[39] <= 1.5\nsquared_error = 0.241\nsamples = 367\nvalue = 11.637'),
Text(0.04379327000483014, 0.15625, 'X[56] <= 0.999\nsquared_error = 0.234\nsamples = 366\nvalue = 11.633'),
Text(0.04347126066655933, 0.09375, 'X[62] <= 0.053\nsquared_error = 0.229\nsamples = 365\nvalue = 11.629'),
Text(0.04314925132828852, 0.03125, 'squared_error = 0.176\nsamples = 14\nvalue = 11.983'),
Text(0.04379327000483014, 0.03125, 'squared_error = 0.226\nsamples = 351\nvalue = 11.615'),
Text(0.04411527934310095, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 13.039'),
Text(0.04443728868137176, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 13.305'),
Text(0.04995169859925938, 0.34375, 'X[22] <= 1.5\nsquared_error = 0.281\nsamples = 69\nvalue = 11.816'),
Text(0.047818386733215264, 0.28125, 'X[61] <= 0.94\nsquared_error = 0.208\nsamples = 54\nvalue = 11.971'),
Text(0.04669135404926743, 0.21875, 'X[62] <= 0.646\nsquared_error = 0.182\nsamples = 52\nvalue = 11.937'),
Text(0.04540331669618419, 0.15625, 'X[45] <= 0.63\nsquared_error = 0.123\nsamples = 26\nvalue = 12.108'),
Text(0.04475929801964257, 0.09375, 'X[45] <= 0.186\nsquared_error = 0.071\nsamples = 15\nvalue = 12.273'),
Text(0.04443728868137176, 0.03125, 'squared_error = 0.004\nsamples = 4\nvalue = 11.956'),
Text(0.04508130735791338, 0.03125, 'squared_error = 0.046\nsamples = 11\nvalue = 12.388'),
Text(0.04604733537272581, 0.09375, 'X[44] <= 0.637\nsquared_error = 0.105\nsamples = 11\nvalue = 11.884'),
Text(0.045725326034455, 0.03125, 'squared_error = 0.007\nsamples = 3\nvalue = 12.236'),
Text(0.046369344710996616, 0.03125, 'squared_error = 0.078\nsamples = 8\nvalue = 11.752'),
Text(0.04797939140235067, 0.15625, 'X[1] <= 1310.0\nsquared_error = 0.183\nsamples = 26\nvalue = 11.765'),
Text(0.047335372725809045, 0.09375, 'X[47] <= 0.536\nsquared_error = 0.156\nsamples = 14\nvalue = 11.539'),
Text(0.04701336338753824, 0.03125, 'squared_error = 0.121\nsamples = 7\nvalue = 11.264'),
Text(0.04765738206407986, 0.03125, 'squared_error = 0.04\nsamples = 7\nvalue = 11.814'),
Text(0.04862341007889229, 0.09375, 'X[10] <= 1.5\nsquared_error = 0.086\nsamples = 12\nvalue = 12.029'),
Text(0.048301400740621475, 0.03125, 'squared_error = 0.04\nsamples = 11\nvalue = 12.097'),
Text(0.0489454194171631, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.29'),
Text(0.0489454194171631, 0.21875, 'X[59] <= 0.209\nsquared_error = 0.061\nsamples = 2\nvalue = 12.859'),
Text(0.04862341007889229, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 13.106'),
Text(0.049267428755433905, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 12.612'),
Text(0.05208501046530349, 0.28125, 'X[58] <= 0.37\nsquared_error = 0.144\nsamples = 15\nvalue = 11.257'),
Text(0.05055546610851715, 0.21875, 'X[45] <= 0.784\nsquared_error = 0.022\nsamples = 5\nvalue = 10.835'),
Text(0.04991144743197553, 0.15625, 'X[60] <= 0.356\nsquared_error = 0.005\nsamples = 3\nvalue = 10.936'),
Text(0.04958943809370472, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.035'),
Text(0.050233456770246335, 0.09375, 'X[18] <= -4.0\nsquared_error = 0.001\nsamples = 2\nvalue = 10.887'),
Text(0.04991144743197553, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.915'),
Text(0.05055546610851715, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.859'),
Text(0.051199484785058764, 0.15625, 'X[45] <= 0.898\nsquared_error = 0.007\nsamples = 2\nvalue = 10.683'),
Text(0.05087747544678796, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.768'),
Text(0.05152149412332958, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.597'),
Text(0.05361455482208984, 0.21875, 'X[45] <= 0.849\nsquared_error = 0.071\nsamples = 10\nvalue = 11.468'),
Text(0.05280953147641282, 0.15625, 'X[45] <= 0.41\nsquared_error = 0.048\nsamples = 8\nvalue = 11.377'),
Text(0.052165512799871194, 0.09375, 'X[51] <= 0.308\nsquared_error = 0.007\nsamples = 2\nvalue = 11.694'),
Text(0.05184350346160039, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.613'),
Text(0.052487522138142007, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.775'),
Text(0.053453550152954436, 0.09375, 'X[58] <= 0.812\nsquared_error = 0.017\nsamples = 6\nvalue = 11.271'),
Text(0.053131540814683624, 0.03125, 'squared_error = 0.006\nsamples = 5\nvalue = 11.222'),
Text(0.05377555949122525, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.513'),
Text(0.054419578167766866, 0.15625, 'X[46] <= 0.191\nsquared_error = 0.0\nsamples = 2\nvalue = 11.831'),
Text(0.054097568829496054, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.849'),
Text(0.05474158750603768, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.813'),
Text(0.06282704073418129, 0.53125, 'X[59] <= 0.013\nsquared_error = 2.146\nsamples = 150\nvalue = 11.071'),
Text(0.06160441152793431, 0.46875, 'X[4] <= 2.5\nsquared_error = 28.394\nsamples = 2\nvalue = 5.329'),
Text(0.0612824021896635, 0.40625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.657'),
Text(0.06192642086620512, 0.40625, 'squared_error = 0.0\nsamples = 1\nvalue = 0.0'),
Text(0.06404966994042827, 0.46875, 'X[11] <= 1.5\nsquared_error = 1.339\nsamples = 148\nvalue = 11.148'),
Text(0.06257043954274674, 0.40625, 'X[50] <= 0.995\nsquared_error = 0.5\nsamples = 146\nvalue = 11.223'),
Text(0.0605780067621961, 0.34375, 'X[62] <= 0.943\nsquared_error = 0.389\nsamples = 143\nvalue = 11.253'),
Text(0.05820318789244888, 0.28125, 'X[49] <= 0.07\nsquared_error = 0.359\nsamples = 134\nvalue = 11.304'),
Text(0.05683464820479794, 0.21875, 'X[61] <= 0.706\nsquared_error = 1.462\nsamples = 8\nvalue = 10.542'),
Text(0.05602962485912091, 0.15625, 'X[0] <= 8250.0\nsquared_error = 0.459\nsamples = 6\nvalue = 11.15'),
Text(0.055385606182579296, 0.09375, 'X[53] <= 0.44\nsquared_error = 0.038\nsamples = 3\nvalue = 10.517'),
Text(0.055063596844308484, 0.03125, 'squared_error = 0.006\nsamples = 2\nvalue = 10.386'),
Text(0.05570761552085011, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.779'),
Text(0.05667364353566253, 0.09375, 'X[57] <= 0.517\nsquared_error = 0.08\nsamples = 3\nvalue = 11.782'),
Text(0.056351634197391726, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.15'),
Text(0.05699565287393334, 0.03125, 'squared_error = 0.019\nsamples = 2\nvalue = 11.599'),
Text(0.05763967155047496, 0.15625, 'X[33] <= 0.5\nsquared_error = 0.041\nsamples = 2\nvalue = 8.72'),
Text(0.057317662212204155, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 8.923'),
Text(0.05796168088874577, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 8.517'),
Text(0.05957172758009982, 0.21875, 'X[48] <= 0.996\nsquared_error = 0.25\nsamples = 126\nvalue = 11.353'),
Text(0.059249718241829015, 0.15625, 'X[45] <= 0.924\nsquared_error = 0.218\nsamples = 125\nvalue = 11.369'),
Text(0.05860569956528739, 0.09375, 'X[45] <= 0.844\nsquared_error = 0.21\nsamples = 119\nvalue = 11.397'),
Text(0.058283690227016585, 0.03125, 'squared_error = 0.201\nsamples = 111\nvalue = 11.367'),
Text(0.0589277089035582, 0.03125, 'squared_error = 0.142\nsamples = 8\nvalue = 11.813'),
Text(0.05989373691837063, 0.09375, 'X[38] <= 1.5\nsquared_error = 0.065\nsamples = 6\nvalue = 10.82'),
Text(0.05957172758009982, 0.03125, 'squared_error = 0.0\nsamples = 4\nvalue = 10.994'),
Text(0.060215746256641445, 0.03125, 'squared_error = 0.015\nsamples = 2\nvalue = 10.474'),
Text(0.05989373691837063, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 9.306'),
Text(0.06295282563194332, 0.28125, 'X[53] <= 0.76\nsquared_error = 0.221\nsamples = 9\nvalue = 10.494'),
Text(0.06263081629367252, 0.21875, 'X[50] <= 0.901\nsquared_error = 0.108\nsamples = 8\nvalue = 10.369'),
Text(0.06182579294799549, 0.15625, 'X[57] <= 0.575\nsquared_error = 0.013\nsamples = 6\nvalue = 10.535'),
Text(0.061181774271453875, 0.09375, 'X[41] <= 0.5\nsquared_error = 0.003\nsamples = 3\nvalue = 10.636'),
Text(0.06085976493318306, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 10.597'),
Text(0.06150378360972468, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.714'),
Text(0.06246981162453711, 0.09375, 'X[52] <= 0.83\nsquared_error = 0.002\nsamples = 3\nvalue = 10.433'),
Text(0.062147802286266304, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 10.463'),
Text(0.06279182096280791, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.373'),
Text(0.06343583963934954, 0.15625, 'X[54] <= 0.47\nsquared_error = 0.065\nsamples = 2\nvalue = 9.871'),
Text(0.06311383030107873, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.127'),
Text(0.06375784897762035, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 9.616'),
Text(0.06327483497021413, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.493'),
Text(0.06456287232329738, 0.34375, 'X[48] <= 0.548\nsquared_error = 3.655\nsamples = 3\nvalue = 9.772'),
Text(0.06424086298502657, 0.28125, 'X[50] <= 0.997\nsquared_error = 0.086\nsamples = 2\nvalue = 11.114'),
Text(0.06391885364675576, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 10.82'),
Text(0.06456287232329738, 0.21875, 'squared_error = -0.0\nsamples = 1\nvalue = 11.408'),
Text(0.06488488166156818, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 7.09'),
Text(0.0655289003381098, 0.40625, 'X[52] <= 0.705\nsquared_error = 32.469\nsamples = 2\nvalue = 5.698'),
Text(0.06520689099983899, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.396'),
Text(0.06585090967638062, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 0.0'),
Text(0.08230105860569957, 0.65625, 'X[1] <= 524.5\nsquared_error = 0.548\nsamples = 1493\nvalue = 11.638'),
Text(0.06919175656094027, 0.59375, 'X[35] <= -2.0\nsquared_error = 16.388\nsamples = 7\nvalue = 9.87'),
Text(0.06886974722266946, 0.53125, 'X[53] <= 0.574\nsquared_error = 0.176\nsamples = 6\nvalue = 11.515'),
Text(0.06806472387699243, 0.46875, 'X[1] <= 420.0\nsquared_error = 0.058\nsamples = 4\nvalue = 11.765'),
Text(0.0674207052004508, 0.40625, 'X[60] <= 0.1\nsquared_error = 0.012\nsamples = 2\nvalue = 11.993'),
Text(0.06709869586218001, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.101'),
Text(0.06774271453872162, 0.34375, 'squared_error = -0.0\nsamples = 1\nvalue = 11.884'),
Text(0.06870874255353406, 0.40625, 'X[22] <= 1.5\nsquared_error = 0.001\nsamples = 2\nvalue = 11.537'),
Text(0.06838673321526324, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.513'),
Text(0.06903075189180487, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.562'),
Text(0.06967477056834648, 0.46875, 'X[55] <= 0.597\nsquared_error = 0.038\nsamples = 2\nvalue = 11.016'),
Text(0.06935276123007567, 0.40625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.212'),
Text(0.06999677990661729, 0.40625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.82'),
Text(0.06951376589921107, 0.53125, 'squared_error = 0.0\nsamples = 1\nvalue = 0.0'),
Text(0.09541036065045887, 0.59375, 'X[8] <= 3.5\nsquared_error = 0.458\nsamples = 1486\nvalue = 11.646'),
Text(0.07988850426662374, 0.53125, 'X[4] <= 2.5\nsquared_error = 0.406\nsamples = 1324\nvalue = 11.619'),
Text(0.07288480115923361, 0.46875, 'X[49] <= 0.973\nsquared_error = 0.444\nsamples = 259\nvalue = 11.473'),
Text(0.07138544517791016, 0.40625, 'X[46] <= 0.989\nsquared_error = 0.245\nsamples = 255\nvalue = 11.499'),
Text(0.06967477056834648, 0.34375, 'X[10] <= 1.5\nsquared_error = 0.234\nsamples = 250\nvalue = 11.483'),
Text(0.06818547737884399, 0.28125, 'X[34] <= 0.5\nsquared_error = 0.22\nsamples = 248\nvalue = 11.493'),
Text(0.06617291901465143, 0.21875, 'X[43] <= 0.707\nsquared_error = 0.42\nsamples = 20\nvalue = 11.141'),
Text(0.06504588633070359, 0.15625, 'X[62] <= 0.787\nsquared_error = 0.127\nsamples = 16\nvalue = 11.39'),
Text(0.06440186765416198, 0.09375, 'X[61] <= 0.331\nsquared_error = 0.067\nsamples = 14\nvalue = 11.487'),
Text(0.06407985831589116, 0.03125, 'squared_error = 0.038\nsamples = 6\nvalue = 11.301'),
Text(0.06472387699243277, 0.03125, 'squared_error = 0.043\nsamples = 8\nvalue = 11.627'),
Text(0.06568990500724521, 0.09375, 'X[41] <= 0.5\nsquared_error = 0.012\nsamples = 2\nvalue = 10.708'),
Text(0.0653678956689744, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.597'),
Text(0.06601191434551602, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.82'),
Text(0.06729995169859926, 0.15625, 'X[61] <= 0.586\nsquared_error = 0.355\nsamples = 4\nvalue = 10.145'),
Text(0.06697794236032845, 0.09375, 'X[45] <= 0.556\nsquared_error = 0.018\nsamples = 3\nvalue = 9.808'),
Text(0.06665593302205763, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 9.903'),
Text(0.06729995169859926, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 9.616'),
Text(0.06762196103687007, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 11.156'),
Text(0.07019803574303655, 0.21875, 'X[55] <= 0.776\nsquared_error = 0.19\nsamples = 228\nvalue = 11.524'),
Text(0.0689099983899533, 0.15625, 'X[54] <= 0.991\nsquared_error = 0.182\nsamples = 184\nvalue = 11.48'),
Text(0.0682659797134117, 0.09375, 'X[49] <= 0.844\nsquared_error = 0.175\nsamples = 181\nvalue = 11.469'),
Text(0.06794397037514088, 0.03125, 'squared_error = 0.166\nsamples = 149\nvalue = 11.426'),
Text(0.0685879890516825, 0.03125, 'squared_error = 0.17\nsamples = 32\nvalue = 11.666'),
Text(0.06955401706649493, 0.09375, 'X[57] <= 0.353\nsquared_error = 0.095\nsamples = 3\nvalue = 12.171'),
Text(0.06923200772822412, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.736'),
Text(0.06987602640476574, 0.03125, 'squared_error = -0.0\nsamples = 2\nvalue = 12.388'),
Text(0.07148607309611979, 0.15625, 'X[58] <= 0.953\nsquared_error = 0.186\nsamples = 44\nvalue = 11.708'),
Text(0.07084205441957817, 0.09375, 'X[58] <= 0.29\nsquared_error = 0.147\nsamples = 42\nvalue = 11.753'),
Text(0.07052004508130735, 0.03125, 'squared_error = 0.144\nsamples = 12\nvalue = 11.471'),
Text(0.07116406375784898, 0.03125, 'squared_error = 0.103\nsamples = 30\nvalue = 11.866'),
Text(0.0721300917726614, 0.09375, 'X[58] <= 0.961\nsquared_error = 0.048\nsamples = 2\nvalue = 10.75'),
Text(0.0718080824343906, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.968'),
Text(0.07245210111093221, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.532'),
Text(0.07116406375784898, 0.28125, 'X[60] <= 0.31\nsquared_error = 0.362\nsamples = 2\nvalue = 10.218'),
Text(0.07084205441957817, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 10.82'),
Text(0.07148607309611979, 0.21875, 'squared_error = -0.0\nsamples = 1\nvalue = 9.616'),
Text(0.07309611978747384, 0.34375, 'X[50] <= 0.751\nsquared_error = 0.088\nsamples = 5\nvalue = 12.326'),
Text(0.07245210111093221, 0.28125, 'X[49] <= 0.373\nsquared_error = 0.003\nsamples = 2\nvalue = 12.635'),
Text(0.0721300917726614, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 12.692'),
Text(0.07277411044920302, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 12.578'),
Text(0.07374013846401546, 0.28125, 'X[0] <= 27684.602\nsquared_error = 0.038\nsamples = 3\nvalue = 12.121'),
Text(0.07341812912574465, 0.21875, 'X[50] <= 0.797\nsquared_error = 0.002\nsamples = 2\nvalue = 12.256'),
Text(0.07309611978747384, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 12.211'),
Text(0.07374013846401546, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 12.301'),
Text(0.07406214780228626, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.849'),
Text(0.07438415714055707, 0.40625, 'X[2] <= 1962.5\nsquared_error = 10.278\nsamples = 4\nvalue = 9.798'),
Text(0.07406214780228626, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 4.248'),
Text(0.07470616647882788, 0.34375, 'X[1] <= 1600.0\nsquared_error = 0.015\nsamples = 3\nvalue = 11.648'),
Text(0.07438415714055707, 0.28125, 'squared_error = 0.0\nsamples = 2\nvalue = 11.736'),
Text(0.0750281758170987, 0.28125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.472'),
Text(0.08689220737401385, 0.46875, 'X[48] <= 0.923\nsquared_error = 0.39\nsamples = 1065\nvalue = 11.654'),
Text(0.08168974400257607, 0.40625, 'X[6] <= 1.5\nsquared_error = 0.261\nsamples = 995\nvalue = 11.675'),
Text(0.07748349702141362, 0.34375, 'X[59] <= 0.989\nsquared_error = 0.414\nsamples = 244\nvalue = 11.542'),
Text(0.07623571083561423, 0.28125, 'X[29] <= 1.5\nsquared_error = 0.255\nsamples = 242\nvalue = 11.57'),
Text(0.07470616647882788, 0.21875, 'X[10] <= 1.5\nsquared_error = 0.239\nsamples = 223\nvalue = 11.538'),
Text(0.07438415714055707, 0.15625, 'X[1] <= 2250.0\nsquared_error = 0.231\nsamples = 221\nvalue = 11.528'),
Text(0.07374013846401546, 0.09375, 'X[51] <= 0.039\nsquared_error = 0.227\nsamples = 174\nvalue = 11.579'),
Text(0.07341812912574465, 0.03125, 'squared_error = 0.079\nsamples = 3\nvalue = 10.67'),
Text(0.07406214780228626, 0.03125, 'squared_error = 0.215\nsamples = 171\nvalue = 11.595'),
Text(0.0750281758170987, 0.09375, 'X[52] <= 0.04\nsquared_error = 0.2\nsamples = 47\nvalue = 11.341'),
Text(0.07470616647882788, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.766'),
Text(0.07535018515536951, 0.03125, 'squared_error = 0.16\nsamples = 46\nvalue = 11.31'),
Text(0.0750281758170987, 0.15625, 'squared_error = -0.0\nsamples = 2\nvalue = 12.612'),
Text(0.07776525519240057, 0.21875, 'X[0] <= 21000.0\nsquared_error = 0.278\nsamples = 19\nvalue = 11.954'),
Text(0.07696023184672356, 0.15625, 'X[57] <= 0.187\nsquared_error = 0.115\nsamples = 13\nvalue = 12.188'),
Text(0.07631621317018193, 0.09375, 'X[59] <= 0.893\nsquared_error = 0.001\nsamples = 2\nvalue = 11.585'),
Text(0.07599420383191112, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.562'),
Text(0.07663822250845274, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.608'),
Text(0.07760425052326518, 0.09375, 'X[56] <= 0.858\nsquared_error = 0.057\nsamples = 11\nvalue = 12.298'),
Text(0.07728224118499437, 0.03125, 'squared_error = 0.023\nsamples = 10\nvalue = 12.358'),
Text(0.07792625986153598, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.695'),
Text(0.0785702785380776, 0.15625, 'X[51] <= 0.414\nsquared_error = 0.257\nsamples = 6\nvalue = 11.448'),
Text(0.07824826919980679, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.468'),
Text(0.07889228787634842, 0.09375, 'X[51] <= 0.632\nsquared_error = 0.058\nsamples = 5\nvalue = 11.244'),
Text(0.0785702785380776, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.82'),
Text(0.07921429721461923, 0.03125, 'squared_error = 0.016\nsamples = 4\nvalue = 11.35'),
Text(0.07873128320721301, 0.28125, 'X[55] <= 0.782\nsquared_error = 8.133\nsamples = 2\nvalue = 8.15'),
Text(0.0784092738689422, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 5.298'),
Text(0.07905329254548382, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.002'),
Text(0.08589599098373853, 0.34375, 'X[9] <= 1.5\nsquared_error = 0.204\nsamples = 751\nvalue = 11.719'),
Text(0.08372242795041056, 0.28125, 'X[1] <= 1650.0\nsquared_error = 0.283\nsamples = 50\nvalue = 12.071'),
Text(0.08211238125905651, 0.21875, 'X[53] <= 0.291\nsquared_error = 0.208\nsamples = 28\nvalue = 11.802'),
Text(0.08082434390597328, 0.15625, 'X[43] <= 0.598\nsquared_error = 0.116\nsamples = 7\nvalue = 11.342'),
Text(0.08018032522943165, 0.09375, 'X[58] <= 0.359\nsquared_error = 0.035\nsamples = 4\nvalue = 11.084'),
Text(0.07985831589116084, 0.03125, 'squared_error = 0.015\nsamples = 3\nvalue = 10.995'),
Text(0.08050233456770246, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.35'),
Text(0.08146836258251489, 0.09375, 'X[53] <= 0.108\nsquared_error = 0.017\nsamples = 3\nvalue = 11.687'),
Text(0.08114635324424409, 0.03125, 'squared_error = 0.005\nsamples = 2\nvalue = 11.606'),
Text(0.0817903719207857, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.849'),
Text(0.08340041861213975, 0.15625, 'X[61] <= 0.952\nsquared_error = 0.145\nsamples = 21\nvalue = 11.956'),
Text(0.08275639993559814, 0.09375, 'X[57] <= 0.024\nsquared_error = 0.096\nsamples = 19\nvalue = 12.029'),
Text(0.08243439059732732, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.794'),
Text(0.08307840927386895, 0.03125, 'squared_error = 0.067\nsamples = 18\nvalue = 11.987'),
Text(0.08404443728868137, 0.09375, 'X[6] <= 3.5\nsquared_error = 0.065\nsamples = 2\nvalue = 11.258'),
Text(0.08372242795041056, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.513'),
Text(0.08436644662695218, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.002'),
Text(0.0853324746417646, 0.21875, 'X[51] <= 0.121\nsquared_error = 0.168\nsamples = 22\nvalue = 12.414'),
Text(0.0850104653034938, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 13.592'),
Text(0.08565448398003542, 0.15625, 'X[60] <= 0.89\nsquared_error = 0.107\nsamples = 21\nvalue = 12.358'),
Text(0.0853324746417646, 0.09375, 'X[61] <= 0.932\nsquared_error = 0.049\nsamples = 20\nvalue = 12.303'),
Text(0.0850104653034938, 0.03125, 'squared_error = 0.017\nsamples = 19\nvalue = 12.344'),
Text(0.08565448398003542, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.513'),
Text(0.08597649331830623, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 13.459'),
Text(0.0880695540170665, 0.28125, 'X[1] <= 1306.5\nsquared_error = 0.189\nsamples = 701\nvalue = 11.694'),
Text(0.08726453067138946, 0.21875, 'X[0] <= 445841.5\nsquared_error = 0.122\nsamples = 164\nvalue = 11.561'),
Text(0.08694252133311867, 0.15625, 'X[34] <= 0.5\nsquared_error = 0.098\nsamples = 163\nvalue = 11.573'),
Text(0.08662051199484785, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.766'),
Text(0.08726453067138946, 0.09375, 'X[53] <= 0.24\nsquared_error = 0.09\nsamples = 162\nvalue = 11.566'),
Text(0.08694252133311867, 0.03125, 'squared_error = 0.07\nsamples = 38\nvalue = 11.705'),
Text(0.08758654000966028, 0.03125, 'squared_error = 0.089\nsamples = 124\nvalue = 11.523'),
Text(0.08758654000966028, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 9.582'),
Text(0.08887457736274353, 0.21875, 'X[1] <= 1318.5\nsquared_error = 0.202\nsamples = 537\nvalue = 11.734'),
Text(0.08855256802447271, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 13.872'),
Text(0.08919658670101432, 0.15625, 'X[16] <= -3.5\nsquared_error = 0.194\nsamples = 536\nvalue = 11.73'),
Text(0.08855256802447271, 0.09375, 'X[55] <= 0.725\nsquared_error = 1.046\nsamples = 3\nvalue = 10.653'),
Text(0.0882305586862019, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 9.21'),
Text(0.08887457736274353, 0.03125, 'squared_error = 0.008\nsamples = 2\nvalue = 11.374'),
Text(0.08984060537755595, 0.09375, 'X[0] <= 11001.5\nsquared_error = 0.183\nsamples = 533\nvalue = 11.736'),
Text(0.08951859603928514, 0.03125, 'squared_error = 0.2\nsamples = 251\nvalue = 11.654'),
Text(0.09016261471582676, 0.03125, 'squared_error = 0.156\nsamples = 282\nvalue = 11.809'),
Text(0.09209467074545162, 0.40625, 'X[58] <= 0.054\nsquared_error = 2.127\nsamples = 70\nvalue = 11.357'),
Text(0.09112864273063918, 0.34375, 'X[6] <= 4.0\nsquared_error = 14.257\nsamples = 5\nvalue = 9.141'),
Text(0.09080663339236839, 0.28125, 'X[52] <= 0.613\nsquared_error = 0.093\nsamples = 4\nvalue = 11.025'),
Text(0.09016261471582676, 0.21875, 'X[48] <= 0.958\nsquared_error = 0.008\nsamples = 2\nvalue = 10.733'),
Text(0.08984060537755595, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.645'),
Text(0.09048462405409757, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.82'),
Text(0.09145065206891, 0.21875, 'X[48] <= 0.954\nsquared_error = 0.008\nsamples = 2\nvalue = 11.316'),
Text(0.09112864273063918, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.225'),
Text(0.09177266140718081, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 11.408'),
Text(0.09145065206891, 0.28125, 'squared_error = -0.0\nsamples = 1\nvalue = 1.609'),
Text(0.09306069876026404, 0.34375, 'X[49] <= 0.04\nsquared_error = 0.787\nsamples = 65\nvalue = 11.527'),
Text(0.09241668008372243, 0.28125, 'X[51] <= 0.683\nsquared_error = 9.845\nsamples = 2\nvalue = 8.213'),
Text(0.09209467074545162, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.35'),
Text(0.09273868942199323, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 5.075'),
Text(0.09370471743680567, 0.28125, 'X[44] <= 0.009\nsquared_error = 0.14\nsamples = 63\nvalue = 11.632'),
Text(0.09338270809853486, 0.21875, 'squared_error = 0.0\nsamples = 2\nvalue = 12.612'),
Text(0.09402672677507648, 0.21875, 'X[47] <= 0.069\nsquared_error = 0.112\nsamples = 61\nvalue = 11.6'),
Text(0.09273868942199323, 0.15625, 'X[0] <= 13125.0\nsquared_error = 0.096\nsamples = 7\nvalue = 12.0'),
Text(0.09209467074545162, 0.09375, 'X[45] <= 0.36\nsquared_error = 0.025\nsamples = 5\nvalue = 11.837'),
Text(0.09177266140718081, 0.03125, 'squared_error = 0.004\nsamples = 2\nvalue = 11.672'),
Text(0.09241668008372243, 0.03125, 'squared_error = 0.009\nsamples = 3\nvalue = 11.947'),
Text(0.09338270809853486, 0.09375, 'X[41] <= 0.5\nsquared_error = 0.041\nsamples = 2\nvalue = 12.409'),
Text(0.09306069876026404, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.612'),
Text(0.09370471743680567, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.206'),
Text(0.09531476412815972, 0.15625, 'X[59] <= 0.031\nsquared_error = 0.091\nsamples = 54\nvalue = 11.548'),
Text(0.09467074545161809, 0.09375, 'X[42] <= -2.0\nsquared_error = 0.002\nsamples = 2\nvalue = 12.254'),
Text(0.09434873611334729, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.301'),
Text(0.0949927547898889, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.206'),
Text(0.09595878280470134, 0.09375, 'X[58] <= 0.616\nsquared_error = 0.074\nsamples = 52\nvalue = 11.521'),
Text(0.09563677346643053, 0.03125, 'squared_error = 0.044\nsamples = 34\nvalue = 11.408'),
Text(0.09628079214297215, 0.03125, 'squared_error = 0.061\nsamples = 18\nvalue = 11.735'),
Text(0.110932217034294, 0.53125, 'X[59] <= 0.829\nsquared_error = 0.833\nsamples = 162\nvalue = 11.868'),
Text(0.10380776042505233, 0.46875, 'X[22] <= 1.5\nsquared_error = 0.362\nsamples = 137\nvalue = 11.968'),
Text(0.09801159233617775, 0.40625, 'X[10] <= -3.0\nsquared_error = 0.273\nsamples = 103\nvalue = 12.114'),
Text(0.09628079214297215, 0.34375, 'X[45] <= 0.451\nsquared_error = 0.281\nsamples = 3\nvalue = 10.997'),
Text(0.09595878280470134, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.309'),
Text(0.09660280148124295, 0.28125, 'X[59] <= 0.474\nsquared_error = 0.067\nsamples = 2\nvalue = 11.341'),
Text(0.09628079214297215, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.599'),
Text(0.09692481081951376, 0.21875, 'squared_error = -0.0\nsamples = 1\nvalue = 11.082'),
Text(0.09974239252938336, 0.34375, 'X[2] <= 1935.0\nsquared_error = 0.234\nsamples = 100\nvalue = 12.147'),
Text(0.0983738528417324, 0.28125, 'X[50] <= 0.73\nsquared_error = 0.096\nsamples = 9\nvalue = 12.684'),
Text(0.09756882949605539, 0.21875, 'X[52] <= 0.701\nsquared_error = 0.014\nsamples = 7\nvalue = 12.839'),
Text(0.09692481081951376, 0.15625, 'X[0] <= 2275.0\nsquared_error = 0.004\nsamples = 5\nvalue = 12.9'),
Text(0.09660280148124295, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 13.017'),
Text(0.09724682015778457, 0.09375, 'X[47] <= 0.569\nsquared_error = 0.001\nsamples = 4\nvalue = 12.87'),
Text(0.09692481081951376, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 12.899'),
Text(0.09756882949605539, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 12.841'),
Text(0.09821284817259701, 0.15625, 'X[51] <= 0.57\nsquared_error = 0.006\nsamples = 2\nvalue = 12.689'),
Text(0.0978908388343262, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.766'),
Text(0.09853485751086781, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 12.612'),
Text(0.09917887618740943, 0.21875, 'X[50] <= 0.776\nsquared_error = 0.004\nsamples = 2\nvalue = 12.139'),
Text(0.09885686684913862, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 12.206'),
Text(0.09950088552568025, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 12.073'),
Text(0.1011109322170343, 0.28125, 'X[1] <= 1050.0\nsquared_error = 0.216\nsamples = 91\nvalue = 12.094'),
Text(0.10078892287876348, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 10.309'),
Text(0.1014329415553051, 0.21875, 'X[0] <= 21780.0\nsquared_error = 0.183\nsamples = 90\nvalue = 12.114'),
Text(0.10014490420222187, 0.15625, 'X[29] <= 1.5\nsquared_error = 0.169\nsamples = 79\nvalue = 12.052'),
Text(0.09950088552568025, 0.09375, 'X[21] <= 1.5\nsquared_error = 0.17\nsamples = 66\nvalue = 11.991'),
Text(0.09917887618740943, 0.03125, 'squared_error = 0.149\nsamples = 65\nvalue = 11.972'),
Text(0.09982289486395106, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 13.218'),
Text(0.10078892287876348, 0.09375, 'X[49] <= 0.233\nsquared_error = 0.052\nsamples = 13\nvalue = 12.36'),
Text(0.10046691354049267, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.96'),
Text(0.1011109322170343, 0.03125, 'squared_error = 0.024\nsamples = 12\nvalue = 12.31'),
Text(0.10272097890838834, 0.15625, 'X[61] <= 0.597\nsquared_error = 0.051\nsamples = 11\nvalue = 12.561'),
Text(0.10207696023184672, 0.09375, 'X[55] <= 0.805\nsquared_error = 0.025\nsamples = 5\nvalue = 12.76'),
Text(0.10175495089357592, 0.03125, 'squared_error = 0.007\nsamples = 3\nvalue = 12.876'),
Text(0.10239896957011753, 0.03125, 'squared_error = 0.001\nsamples = 2\nvalue = 12.586'),
Text(0.10336499758492997, 0.09375, 'X[55] <= 0.389\nsquared_error = 0.013\nsamples = 6\nvalue = 12.396'),
Text(0.10304298824665915, 0.03125, 'squared_error = 0.003\nsamples = 4\nvalue = 12.467'),
Text(0.10368700692320078, 0.03125, 'squared_error = 0.002\nsamples = 2\nvalue = 12.254'),
Text(0.1096039285139269, 0.40625, 'X[57] <= 0.303\nsquared_error = 0.373\nsamples = 34\nvalue = 11.527'),
Text(0.10698760264047658, 0.34375, 'X[55] <= 0.598\nsquared_error = 0.519\nsamples = 10\nvalue = 11.058'),
Text(0.10578006762196104, 0.28125, 'X[44] <= 0.865\nsquared_error = 0.285\nsamples = 7\nvalue = 10.715'),
Text(0.10497504427628401, 0.21875, 'X[51] <= 0.386\nsquared_error = 0.083\nsamples = 5\nvalue = 10.434'),
Text(0.10433102559974239, 0.15625, 'X[9] <= 1.5\nsquared_error = 0.025\nsamples = 2\nvalue = 10.756'),
Text(0.10400901626147158, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.915'),
Text(0.1046530349380132, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 10.597'),
Text(0.10561906295282564, 0.15625, 'X[46] <= 0.275\nsquared_error = 0.006\nsamples = 3\nvalue = 10.219'),
Text(0.10529705361455483, 0.09375, 'X[22] <= 2.5\nsquared_error = 0.002\nsamples = 2\nvalue = 10.265'),
Text(0.10497504427628401, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.222'),
Text(0.10561906295282564, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.309'),
Text(0.10594107229109644, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 10.127'),
Text(0.10658509096763806, 0.21875, 'X[0] <= 24434.602\nsquared_error = 0.102\nsamples = 2\nvalue = 11.417'),
Text(0.10626308162936725, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.097'),
Text(0.10690710030590887, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 11.736'),
Text(0.10819513765899211, 0.28125, 'X[47] <= 0.545\nsquared_error = 0.148\nsamples = 3\nvalue = 11.86'),
Text(0.1078731283207213, 0.21875, 'X[44] <= 0.523\nsquared_error = 0.027\nsamples = 2\nvalue = 12.115'),
Text(0.1075511189824505, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 12.278'),
Text(0.10819513765899211, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.951'),
Text(0.10851714699726292, 0.21875, 'squared_error = -0.0\nsamples = 1\nvalue = 11.35'),
Text(0.11222025438737723, 0.34375, 'X[61] <= 0.992\nsquared_error = 0.182\nsamples = 24\nvalue = 11.723'),
Text(0.11189824504910642, 0.28125, 'X[58] <= 0.692\nsquared_error = 0.061\nsamples = 23\nvalue = 11.796'),
Text(0.11012719368861697, 0.21875, 'X[57] <= 0.599\nsquared_error = 0.054\nsamples = 16\nvalue = 11.706'),
Text(0.10883915633553373, 0.15625, 'X[46] <= 0.167\nsquared_error = 0.044\nsamples = 8\nvalue = 11.561'),
Text(0.10819513765899211, 0.09375, 'X[57] <= 0.438\nsquared_error = 0.021\nsamples = 2\nvalue = 11.839'),
Text(0.1078731283207213, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.983'),
Text(0.10851714699726292, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.695'),
Text(0.10948317501207536, 0.09375, 'X[38] <= 1.5\nsquared_error = 0.017\nsamples = 6\nvalue = 11.468'),
Text(0.10916116567380454, 0.03125, 'squared_error = 0.004\nsamples = 5\nvalue = 11.415'),
Text(0.10980518435034615, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.736'),
Text(0.11141523104170022, 0.15625, 'X[48] <= 0.45\nsquared_error = 0.022\nsamples = 8\nvalue = 11.852'),
Text(0.11077121236515859, 0.09375, 'X[55] <= 0.461\nsquared_error = 0.006\nsamples = 2\nvalue = 12.052'),
Text(0.11044920302688778, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.128'),
Text(0.1110932217034294, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.977'),
Text(0.11205924971824183, 0.09375, 'X[44] <= 0.655\nsquared_error = 0.009\nsamples = 6\nvalue = 11.785'),
Text(0.11173724037997101, 0.03125, 'squared_error = 0.001\nsamples = 4\nvalue = 11.851'),
Text(0.11238125905651264, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 11.653'),
Text(0.11366929640959587, 0.21875, 'X[52] <= 0.39\nsquared_error = 0.019\nsamples = 7\nvalue = 12.0'),
Text(0.11302527773305426, 0.15625, 'X[51] <= 0.094\nsquared_error = 0.001\nsamples = 2\nvalue = 12.18'),
Text(0.11270326839478345, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.155'),
Text(0.11334728707132506, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.206'),
Text(0.1143133150861375, 0.15625, 'X[2] <= 1989.0\nsquared_error = 0.007\nsamples = 5\nvalue = 11.928'),
Text(0.11399130574786669, 0.09375, 'X[28] <= 0.5\nsquared_error = 0.002\nsamples = 4\nvalue = 11.966'),
Text(0.11366929640959587, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 11.925'),
Text(0.1143133150861375, 0.03125, 'squared_error = 0.001\nsamples = 2\nvalue = 12.007'),
Text(0.11463532442440831, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 11.775'),
Text(0.11254226372564805, 0.28125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.043'),
Text(0.11805667364353566, 0.46875, 'X[59] <= 0.836\nsquared_error = 3.056\nsamples = 25\nvalue = 11.316'),
Text(0.11705039446143937, 0.40625, 'X[53] <= 0.732\nsquared_error = 0.002\nsamples = 2\nvalue = 5.569'),
Text(0.11672838512316858, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 5.521'),
Text(0.11737240379971019, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 5.617'),
Text(0.11906295282563194, 0.40625, 'X[53] <= 0.918\nsquared_error = 0.2\nsamples = 23\nvalue = 11.816'),
Text(0.11801642247625181, 0.34375, 'X[61] <= 0.909\nsquared_error = 0.128\nsamples = 21\nvalue = 11.729'),
Text(0.11688938979230398, 0.28125, 'X[54] <= 0.096\nsquared_error = 0.079\nsamples = 18\nvalue = 11.815'),
Text(0.11656738045403317, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.082'),
Text(0.11721139913057478, 0.21875, 'X[51] <= 0.453\nsquared_error = 0.051\nsamples = 17\nvalue = 11.858'),
Text(0.11592336177749155, 0.15625, 'X[27] <= 0.5\nsquared_error = 0.043\nsamples = 6\nvalue = 12.061'),
Text(0.11527934310094992, 0.09375, 'X[52] <= 0.412\nsquared_error = 0.009\nsamples = 4\nvalue = 11.932'),
Text(0.11495733376267912, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.783'),
Text(0.11560135243922073, 0.03125, 'squared_error = 0.003\nsamples = 3\nvalue = 11.982'),
Text(0.11656738045403317, 0.09375, 'X[62] <= 0.356\nsquared_error = 0.012\nsamples = 2\nvalue = 12.318'),
Text(0.11624537111576236, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.206'),
Text(0.11688938979230398, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.429'),
Text(0.11849943648365803, 0.15625, 'X[52] <= 0.223\nsquared_error = 0.02\nsamples = 11\nvalue = 11.747'),
Text(0.1178554178071164, 0.09375, 'X[47] <= 0.216\nsquared_error = 0.004\nsamples = 2\nvalue = 11.981'),
Text(0.1175334084688456, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.918'),
Text(0.11817742714538722, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.044'),
Text(0.11914345516019964, 0.09375, 'X[51] <= 0.959\nsquared_error = 0.009\nsamples = 9\nvalue = 11.695'),
Text(0.11882144582192884, 0.03125, 'squared_error = 0.005\nsamples = 6\nvalue = 11.747'),
Text(0.11946546449847045, 0.03125, 'squared_error = 0.0\nsamples = 3\nvalue = 11.593'),
Text(0.11914345516019964, 0.28125, 'X[51] <= 0.156\nsquared_error = 0.112\nsamples = 3\nvalue = 11.216'),
Text(0.11882144582192884, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.653'),
Text(0.11946546449847045, 0.21875, 'X[45] <= 0.473\nsquared_error = 0.025\nsamples = 2\nvalue = 10.998'),
Text(0.11914345516019964, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.84'),
Text(0.11978747383674127, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.156'),
Text(0.12010948317501208, 0.34375, 'X[58] <= 0.612\nsquared_error = 0.049\nsamples = 2\nvalue = 12.727'),
Text(0.11978747383674127, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.506'),
Text(0.12043149251328289, 0.28125, 'squared_error = -0.0\nsamples = 1\nvalue = 12.948'),
Text(0.17093035541780713, 0.71875, 'X[42] <= -2.5\nsquared_error = 0.684\nsamples = 2468\nvalue = 11.231'),
Text(0.15910783287715344, 0.65625, 'X[8] <= 3.5\nsquared_error = 0.913\nsamples = 1001\nvalue = 11.053'),
Text(0.14441112542263726, 0.59375, 'X[6] <= 1.5\nsquared_error = 0.919\nsamples = 947\nvalue = 11.016'),
Text(0.13016221220415392, 0.53125, 'X[1] <= 686.0\nsquared_error = 0.981\nsamples = 484\nvalue = 10.859'),
Text(0.12294719046852359, 0.46875, 'X[10] <= 1.5\nsquared_error = 5.368\nsamples = 25\nvalue = 9.989'),
Text(0.12262518113025278, 0.40625, 'X[54] <= 0.08\nsquared_error = 1.261\nsamples = 24\nvalue = 10.405'),
Text(0.12139752052809531, 0.34375, 'X[45] <= 0.171\nsquared_error = 1.325\nsamples = 2\nvalue = 7.366'),
Text(0.1210755111898245, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 6.215'),
Text(0.12171952986636612, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 8.517'),
Text(0.12385284173241023, 0.34375, 'X[8] <= 1.5\nsquared_error = 0.339\nsamples = 22\nvalue = 10.681'),
Text(0.12236354854290775, 0.28125, 'X[47] <= 0.334\nsquared_error = 0.045\nsamples = 3\nvalue = 9.915'),
Text(0.12204153920463694, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 9.616'),
Text(0.12268555788117855, 0.21875, 'X[47] <= 0.477\nsquared_error = 0.0\nsamples = 2\nvalue = 10.065'),
Text(0.12236354854290775, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.043'),
Text(0.12300756721944936, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.086'),
Text(0.12534213492191273, 0.28125, 'X[53] <= 0.247\nsquared_error = 0.278\nsamples = 19\nvalue = 10.802'),
Text(0.1239735952342618, 0.21875, 'X[59] <= 0.368\nsquared_error = 0.067\nsamples = 5\nvalue = 10.295'),
Text(0.12365158589599098, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.714'),
Text(0.12429560457253261, 0.15625, 'X[48] <= 0.644\nsquared_error = 0.028\nsamples = 4\nvalue = 10.19'),
Text(0.1239735952342618, 0.09375, 'X[52] <= 0.635\nsquared_error = 0.001\nsamples = 3\nvalue = 10.286'),
Text(0.12365158589599098, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 10.309'),
Text(0.12429560457253261, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.24'),
Text(0.12461761391080341, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 9.903'),
Text(0.12671067460956367, 0.21875, 'X[55] <= 0.796\nsquared_error = 0.23\nsamples = 14\nvalue = 10.983'),
Text(0.12590565126388664, 0.15625, 'X[54] <= 0.417\nsquared_error = 0.166\nsamples = 11\nvalue = 11.146'),
Text(0.12526163258734505, 0.09375, 'X[8] <= 2.5\nsquared_error = 0.02\nsamples = 4\nvalue = 10.763'),
Text(0.12493962324907422, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.002'),
Text(0.12558364192561583, 0.03125, 'squared_error = 0.001\nsamples = 3\nvalue = 10.684'),
Text(0.12654966994042827, 0.09375, 'X[53] <= 0.614\nsquared_error = 0.118\nsamples = 7\nvalue = 11.364'),
Text(0.12622766060215745, 0.03125, 'squared_error = 0.046\nsamples = 3\nvalue = 11.018'),
Text(0.12687167927869908, 0.03125, 'squared_error = 0.015\nsamples = 4\nvalue = 11.623'),
Text(0.1275156979552407, 0.15625, 'X[57] <= 0.32\nsquared_error = 0.012\nsamples = 3\nvalue = 10.388'),
Text(0.1271936886169699, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.545'),
Text(0.12783770729351152, 0.09375, 'squared_error = -0.0\nsamples = 2\nvalue = 10.309'),
Text(0.12326919980679439, 0.40625, 'squared_error = 0.0\nsamples = 1\nvalue = 0.0'),
Text(0.13737723393978427, 0.46875, 'X[48] <= 0.051\nsquared_error = 0.698\nsamples = 459\nvalue = 10.906'),
Text(0.1312993076799227, 0.40625, 'X[62] <= 0.028\nsquared_error = 2.904\nsamples = 22\nvalue = 10.172'),
Text(0.13097729834165192, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 4.248'),
Text(0.13162131701819352, 0.34375, 'X[49] <= 0.028\nsquared_error = 1.292\nsamples = 21\nvalue = 10.454'),
Text(0.1312993076799227, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 6.908'),
Text(0.13194332635646433, 0.28125, 'X[56] <= 0.461\nsquared_error = 0.696\nsamples = 20\nvalue = 10.632'),
Text(0.12960875865400096, 0.21875, 'X[47] <= 0.404\nsquared_error = 0.711\nsamples = 7\nvalue = 9.85'),
Text(0.12880373530832395, 0.15625, 'X[26] <= 1.5\nsquared_error = 0.206\nsamples = 3\nvalue = 9.019'),
Text(0.12848172597005314, 0.09375, 'X[60] <= 0.674\nsquared_error = 0.041\nsamples = 2\nvalue = 8.72'),
Text(0.12815971663178233, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 8.517'),
Text(0.12880373530832395, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 8.923'),
Text(0.12912574464659476, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 9.616'),
Text(0.13041378199967799, 0.15625, 'X[57] <= 0.364\nsquared_error = 0.184\nsamples = 4\nvalue = 10.473'),
Text(0.12976976332313636, 0.09375, 'X[0] <= 5250.0\nsquared_error = 0.059\nsamples = 2\nvalue = 10.839'),
Text(0.12944775398486555, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.597'),
Text(0.13009177266140717, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.082'),
Text(0.1310578006762196, 0.09375, 'X[55] <= 0.9\nsquared_error = 0.041\nsamples = 2\nvalue = 10.106'),
Text(0.1307357913379488, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.309'),
Text(0.13137981001449042, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 9.903'),
Text(0.1342778940589277, 0.21875, 'X[47] <= 0.261\nsquared_error = 0.182\nsamples = 13\nvalue = 11.053'),
Text(0.13298985670584446, 0.15625, 'X[20] <= 1.5\nsquared_error = 0.072\nsamples = 4\nvalue = 11.526'),
Text(0.13234583802930286, 0.09375, 'X[45] <= 0.366\nsquared_error = 0.007\nsamples = 2\nvalue = 11.787'),
Text(0.13202382869103205, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.871'),
Text(0.13266784736757367, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.704'),
Text(0.13363387538238608, 0.09375, 'X[0] <= 6015.0\nsquared_error = 0.0\nsamples = 2\nvalue = 11.264'),
Text(0.13331186604411527, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.277'),
Text(0.1339558847206569, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.252'),
Text(0.13556593141201095, 0.15625, 'X[22] <= 1.5\nsquared_error = 0.087\nsamples = 9\nvalue = 10.842'),
Text(0.13492191273546933, 0.09375, 'X[46] <= 0.199\nsquared_error = 0.033\nsamples = 6\nvalue = 11.013'),
Text(0.13459990339719852, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.669'),
Text(0.13524392207374014, 0.03125, 'squared_error = 0.012\nsamples = 5\nvalue = 11.082'),
Text(0.13620995008855258, 0.09375, 'X[41] <= 0.5\nsquared_error = 0.018\nsamples = 3\nvalue = 10.501'),
Text(0.13588794075028177, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 10.597'),
Text(0.1365319594268234, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.309'),
Text(0.1434551601996458, 0.40625, 'X[15] <= -3.5\nsquared_error = 0.559\nsamples = 437\nvalue = 10.943'),
Text(0.14313315086137499, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 14.226'),
Text(0.1437771695379166, 0.34375, 'X[8] <= 1.5\nsquared_error = 0.535\nsamples = 436\nvalue = 10.935'),
Text(0.1405570761552085, 0.28125, 'X[35] <= -2.5\nsquared_error = 0.764\nsamples = 54\nvalue = 10.562'),
Text(0.13830301078731283, 0.21875, 'X[52] <= 0.096\nsquared_error = 0.422\nsamples = 39\nvalue = 10.789'),
Text(0.137175978103365, 0.15625, 'X[47] <= 0.602\nsquared_error = 0.113\nsamples = 4\nvalue = 11.817'),
Text(0.13685396876509417, 0.09375, 'squared_error = 0.0\nsamples = 2\nvalue = 11.513'),
Text(0.1374979874416358, 0.09375, 'X[47] <= 0.806\nsquared_error = 0.041\nsamples = 2\nvalue = 12.121'),
Text(0.137175978103365, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.918'),
Text(0.1378199967799066, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.324'),
Text(0.13943004347126067, 0.15625, 'X[52] <= 0.954\nsquared_error = 0.323\nsamples = 35\nvalue = 10.671'),
Text(0.13878602479471905, 0.09375, 'X[47] <= 0.944\nsquared_error = 0.241\nsamples = 32\nvalue = 10.765'),
Text(0.13846401545644824, 0.03125, 'squared_error = 0.186\nsamples = 31\nvalue = 10.809'),
Text(0.13910803413298986, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 9.393'),
Text(0.1400740621478023, 0.09375, 'X[58] <= 0.235\nsquared_error = 0.107\nsamples = 3\nvalue = 9.672'),
Text(0.13975205280953149, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 9.21'),
Text(0.1403960714860731, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 9.903'),
Text(0.14281114152310417, 0.21875, 'X[49] <= 0.718\nsquared_error = 1.173\nsamples = 15\nvalue = 9.973'),
Text(0.14200611817742714, 0.15625, 'X[53] <= 0.844\nsquared_error = 0.58\nsamples = 11\nvalue = 10.46'),
Text(0.14136209950088552, 0.09375, 'X[49] <= 0.435\nsquared_error = 0.285\nsamples = 9\nvalue = 10.738'),
Text(0.1410400901626147, 0.03125, 'squared_error = 0.106\nsamples = 6\nvalue = 10.417'),
Text(0.14168410883915633, 0.03125, 'squared_error = 0.024\nsamples = 3\nvalue = 11.38'),
Text(0.14265013685396877, 0.09375, 'X[2] <= 1919.5\nsquared_error = 0.0\nsamples = 2\nvalue = 9.21'),
Text(0.14232812751569796, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 9.21'),
Text(0.14297214619223958, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 9.21'),
Text(0.1436161648687812, 0.15625, 'X[60] <= 0.215\nsquared_error = 0.359\nsamples = 4\nvalue = 8.635'),
Text(0.1432941555305104, 0.09375, 'squared_error = 0.0\nsamples = 2\nvalue = 9.21'),
Text(0.14393817420705202, 0.09375, 'X[48] <= 0.396\nsquared_error = 0.055\nsamples = 2\nvalue = 8.059'),
Text(0.1436161648687812, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 7.824'),
Text(0.1442601835453228, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 8.294'),
Text(0.1469972629206247, 0.28125, 'X[4] <= 4.5\nsquared_error = 0.48\nsamples = 382\nvalue = 10.988'),
Text(0.14619223957494767, 0.21875, 'X[61] <= 0.99\nsquared_error = 0.454\nsamples = 375\nvalue = 10.97'),
Text(0.14587023023667686, 0.15625, 'X[7] <= 1.5\nsquared_error = 0.439\nsamples = 374\nvalue = 10.976'),
Text(0.14522621156013524, 0.09375, 'X[48] <= 0.975\nsquared_error = 0.52\nsamples = 48\nvalue = 10.683'),
Text(0.14490420222186443, 0.03125, 'squared_error = 0.366\nsamples = 45\nvalue = 10.777'),
Text(0.14554822089840605, 0.03125, 'squared_error = 0.721\nsamples = 3\nvalue = 9.278'),
Text(0.1465142489132185, 0.09375, 'X[62] <= 0.017\nsquared_error = 0.413\nsamples = 326\nvalue = 11.02'),
Text(0.14619223957494767, 0.03125, 'squared_error = 0.431\nsamples = 6\nvalue = 11.807'),
Text(0.1468362582514893, 0.03125, 'squared_error = 0.401\nsamples = 320\nvalue = 11.005'),
Text(0.1465142489132185, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 8.517'),
Text(0.14780228626630174, 0.21875, 'X[21] <= 1.5\nsquared_error = 0.889\nsamples = 7\nvalue = 11.971'),
Text(0.14748027692803092, 0.15625, 'X[1] <= 1466.0\nsquared_error = 0.209\nsamples = 6\nvalue = 11.627'),
Text(0.1471582675897601, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.714'),
Text(0.14780228626630174, 0.09375, 'X[58] <= 0.559\nsquared_error = 0.051\nsamples = 5\nvalue = 11.81'),
Text(0.14748027692803092, 0.03125, 'squared_error = 0.015\nsamples = 3\nvalue = 11.976'),
Text(0.14812429560457252, 0.03125, 'squared_error = 0.002\nsamples = 2\nvalue = 11.561'),
Text(0.14812429560457252, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 14.036'),
Text(0.1586600386411206, 0.53125, 'X[62] <= 1.0\nsquared_error = 0.801\nsamples = 463\nvalue = 11.18'),
Text(0.1583380293028498, 0.46875, 'X[4] <= 2.5\nsquared_error = 0.77\nsamples = 462\nvalue = 11.189'),
Text(0.15482611495733375, 0.40625, 'X[50] <= 0.991\nsquared_error = 0.663\nsamples = 188\nvalue = 11.001'),
Text(0.15315569151505393, 0.34375, 'X[45] <= 0.97\nsquared_error = 0.482\nsamples = 186\nvalue = 11.032'),
Text(0.1507808726453067, 0.28125, 'X[9] <= 1.5\nsquared_error = 0.435\nsamples = 180\nvalue = 11.0'),
Text(0.14941233295765577, 0.21875, 'X[6] <= 2.5\nsquared_error = 0.072\nsamples = 7\nvalue = 11.759'),
Text(0.14876831428111414, 0.15625, 'X[53] <= 0.818\nsquared_error = 0.003\nsamples = 2\nvalue = 12.153'),
Text(0.14844630494284333, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.206'),
Text(0.14909032361938496, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.101'),
Text(0.1500563516341974, 0.15625, 'X[21] <= 1.5\nsquared_error = 0.013\nsamples = 5\nvalue = 11.602'),
Text(0.14973434229592658, 0.09375, 'X[51] <= 0.691\nsquared_error = 0.002\nsamples = 2\nvalue = 11.735'),
Text(0.14941233295765577, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.775'),
Text(0.1500563516341974, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.695'),
Text(0.1503783609724682, 0.09375, 'squared_error = -0.0\nsamples = 3\nvalue = 11.513'),
Text(0.15214941233295765, 0.21875, 'X[59] <= 0.022\nsquared_error = 0.426\nsamples = 173\nvalue = 10.969'),
Text(0.15134438898728064, 0.15625, 'X[47] <= 0.667\nsquared_error = 0.378\nsamples = 3\nvalue = 12.089'),
Text(0.15102237964900983, 0.09375, 'X[49] <= 0.118\nsquared_error = 0.008\nsamples = 2\nvalue = 12.52'),
Text(0.15070037031073902, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.612'),
Text(0.15134438898728064, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 12.429'),
Text(0.15166639832555145, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 11.225'),
Text(0.15295443567863468, 0.15625, 'X[54] <= 0.994\nsquared_error = 0.404\nsamples = 170\nvalue = 10.949'),
Text(0.15231041700209305, 0.09375, 'X[2] <= 1987.5\nsquared_error = 0.383\nsamples = 168\nvalue = 10.933'),
Text(0.15198840766382224, 0.03125, 'squared_error = 0.355\nsamples = 165\nvalue = 10.953'),
Text(0.15263242634036386, 0.03125, 'squared_error = 0.67\nsamples = 3\nvalue = 9.821'),
Text(0.1535984543551763, 0.09375, 'X[4] <= 1.5\nsquared_error = 0.179\nsamples = 2\nvalue = 12.342'),
Text(0.1532764450169055, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.766'),
Text(0.1539204636934471, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.918'),
Text(0.15553051038480115, 0.28125, 'X[2] <= 1955.0\nsquared_error = 0.906\nsamples = 6\nvalue = 12.003'),
Text(0.15488649170825955, 0.21875, 'X[54] <= 0.745\nsquared_error = 0.191\nsamples = 4\nvalue = 11.386'),
Text(0.15456448236998874, 0.15625, 'X[57] <= 0.891\nsquared_error = 0.007\nsamples = 3\nvalue = 11.634'),
Text(0.15424247303171792, 0.09375, 'squared_error = 0.0\nsamples = 2\nvalue = 11.695'),
Text(0.15488649170825955, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 11.513'),
Text(0.15520850104653036, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 10.641'),
Text(0.15617452906134277, 0.21875, 'X[59] <= 0.327\nsquared_error = 0.049\nsamples = 2\nvalue = 13.238'),
Text(0.15585251972307196, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 13.017'),
Text(0.15649653839961358, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 13.459'),
Text(0.15649653839961358, 0.34375, 'X[58] <= 0.555\nsquared_error = 9.064\nsamples = 2\nvalue = 8.117'),
Text(0.15617452906134277, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 5.106'),
Text(0.1568185477378844, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.127'),
Text(0.1618499436483658, 0.40625, 'X[62] <= 0.034\nsquared_error = 0.803\nsamples = 274\nvalue = 11.318'),
Text(0.15850909676380615, 0.34375, 'X[49] <= 0.166\nsquared_error = 8.605\nsamples = 14\nvalue = 10.385'),
Text(0.15818708742553533, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 0.0'),
Text(0.15883110610207696, 0.28125, 'X[1] <= 1650.0\nsquared_error = 0.333\nsamples = 13\nvalue = 11.183'),
Text(0.15794558042183224, 0.21875, 'X[60] <= 0.356\nsquared_error = 0.184\nsamples = 10\nvalue = 10.95'),
Text(0.1571405570761552, 0.15625, 'X[46] <= 0.591\nsquared_error = 0.035\nsamples = 4\nvalue = 10.547'),
Text(0.15649653839961358, 0.09375, 'X[53] <= 0.674\nsquared_error = 0.012\nsamples = 2\nvalue = 10.708'),
Text(0.15617452906134277, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.597'),
Text(0.1568185477378844, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.82'),
Text(0.15778457575269683, 0.09375, 'X[62] <= 0.02\nsquared_error = 0.006\nsamples = 2\nvalue = 10.386'),
Text(0.15746256641442602, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.309'),
Text(0.15810658509096764, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.463'),
Text(0.15875060376750927, 0.15625, 'X[46] <= 0.059\nsquared_error = 0.103\nsamples = 6\nvalue = 11.219'),
Text(0.15842859442923846, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.918'),
Text(0.15907261310578008, 0.09375, 'X[1] <= 1225.0\nsquared_error = 0.007\nsamples = 5\nvalue = 11.079'),
Text(0.15875060376750927, 0.03125, 'squared_error = 0.002\nsamples = 4\nvalue = 11.042'),
Text(0.15939462244405087, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.225'),
Text(0.15971663178232168, 0.21875, 'X[43] <= 0.66\nsquared_error = 0.044\nsamples = 3\nvalue = 11.961'),
Text(0.15939462244405087, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.695'),
Text(0.1600386411205925, 0.15625, 'X[54] <= 0.711\nsquared_error = 0.012\nsamples = 2\nvalue = 12.095'),
Text(0.15971663178232168, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.983'),
Text(0.1603606504588633, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 12.206'),
Text(0.16519079053292546, 0.34375, 'X[52] <= 0.995\nsquared_error = 0.333\nsamples = 260\nvalue = 11.368'),
Text(0.16486878119465465, 0.28125, 'X[0] <= 90200.0\nsquared_error = 0.303\nsamples = 259\nvalue = 11.357'),
Text(0.16293672516502977, 0.21875, 'X[54] <= 0.762\nsquared_error = 0.235\nsamples = 230\nvalue = 11.309'),
Text(0.16164868781194655, 0.15625, 'X[60] <= 0.973\nsquared_error = 0.225\nsamples = 177\nvalue = 11.362'),
Text(0.16100466913540493, 0.09375, 'X[60] <= 0.667\nsquared_error = 0.214\nsamples = 174\nvalue = 11.376'),
Text(0.16068265979713411, 0.03125, 'squared_error = 0.2\nsamples = 122\nvalue = 11.3'),
Text(0.16132667847367574, 0.03125, 'squared_error = 0.204\nsamples = 52\nvalue = 11.554'),
Text(0.16229270648848818, 0.09375, 'X[15] <= 1.5\nsquared_error = 0.231\nsamples = 3\nvalue = 10.575'),
Text(0.16197069715021736, 0.03125, 'squared_error = 0.008\nsamples = 2\nvalue = 10.911'),
Text(0.162614715826759, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 9.903'),
Text(0.16422476251811302, 0.15625, 'X[48] <= 0.197\nsquared_error = 0.225\nsamples = 53\nvalue = 11.132'),
Text(0.1635807438415714, 0.09375, 'X[50] <= 0.973\nsquared_error = 0.15\nsamples = 15\nvalue = 11.433'),
Text(0.16325873450330058, 0.03125, 'squared_error = 0.064\nsamples = 14\nvalue = 11.513'),
Text(0.1639027531798422, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 10.309'),
Text(0.16486878119465465, 0.09375, 'X[49] <= 0.885\nsquared_error = 0.205\nsamples = 38\nvalue = 11.013'),
Text(0.16454677185638383, 0.03125, 'squared_error = 0.159\nsamples = 34\nvalue = 10.934'),
Text(0.16519079053292546, 0.03125, 'squared_error = 0.098\nsamples = 4\nvalue = 11.681'),
Text(0.1668008372242795, 0.21875, 'X[46] <= 0.99\nsquared_error = 0.685\nsamples = 29\nvalue = 11.733'),
Text(0.1664788278860087, 0.15625, 'X[61] <= 0.937\nsquared_error = 0.474\nsamples = 28\nvalue = 11.823'),
Text(0.1661568185477379, 0.09375, 'X[48] <= 0.6\nsquared_error = 0.34\nsamples = 27\nvalue = 11.749'),
Text(0.16583480920946708, 0.03125, 'squared_error = 0.205\nsamples = 19\nvalue = 11.971'),
Text(0.1664788278860087, 0.03125, 'squared_error = 0.265\nsamples = 8\nvalue = 11.222'),
Text(0.1668008372242795, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 13.816'),
Text(0.1671228465625503, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 9.21'),
Text(0.16551279987119627, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 14.226'),
Text(0.1589820479793914, 0.46875, 'squared_error = -0.0\nsamples = 1\nvalue = 7.313'),
Text(0.17380454033166962, 0.59375, 'X[60] <= 0.881\nsquared_error = 0.36\nsamples = 54\nvalue = 11.711'),
Text(0.1705039446143938, 0.53125, 'X[47] <= 0.2\nsquared_error = 0.271\nsamples = 50\nvalue = 11.789'),
Text(0.16808887457736274, 0.46875, 'X[20] <= 1.5\nsquared_error = 0.098\nsamples = 7\nvalue = 11.268'),
Text(0.16776686523909193, 0.40625, 'X[53] <= 0.085\nsquared_error = 0.049\nsamples = 6\nvalue = 11.171'),
Text(0.16744485590082112, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.714'),
Text(0.16808887457736274, 0.34375, 'X[58] <= 0.552\nsquared_error = 0.009\nsamples = 5\nvalue = 11.263'),
Text(0.16776686523909193, 0.28125, 'X[54] <= 0.382\nsquared_error = 0.001\nsamples = 4\nvalue = 11.308'),
Text(0.16744485590082112, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.362'),
Text(0.16808887457736274, 0.21875, 'squared_error = 0.0\nsamples = 3\nvalue = 11.29'),
Text(0.16841088391563355, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.082'),
Text(0.16841088391563355, 0.40625, 'squared_error = -0.0\nsamples = 1\nvalue = 11.849'),
Text(0.1729190146514249, 0.46875, 'X[55] <= 0.026\nsquared_error = 0.248\nsamples = 43\nvalue = 11.874'),
Text(0.17259700531315408, 0.40625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.434'),
Text(0.1732410239896957, 0.40625, 'X[44] <= 0.869\nsquared_error = 0.204\nsamples = 42\nvalue = 11.908'),
Text(0.17034293994525843, 0.34375, 'X[57] <= 0.046\nsquared_error = 0.129\nsamples = 35\nvalue = 12.008'),
Text(0.1700209306069876, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.947'),
Text(0.1706649492835292, 0.28125, 'X[62] <= 0.664\nsquared_error = 0.099\nsamples = 34\nvalue = 12.04'),
Text(0.16873289325390436, 0.21875, 'X[51] <= 0.093\nsquared_error = 0.091\nsamples = 19\nvalue = 12.16'),
Text(0.16792786990822733, 0.15625, 'X[51] <= 0.079\nsquared_error = 0.002\nsamples = 3\nvalue = 12.554'),
Text(0.16760586056995652, 0.09375, 'X[55] <= 0.725\nsquared_error = 0.0\nsamples = 2\nvalue = 12.525'),
Text(0.1672838512316857, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.525'),
Text(0.16792786990822733, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.525'),
Text(0.16824987924649815, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 12.612'),
Text(0.1695379165995814, 0.15625, 'X[1] <= 1150.0\nsquared_error = 0.074\nsamples = 16\nvalue = 12.087'),
Text(0.16889389792303977, 0.09375, 'X[43] <= 0.455\nsquared_error = 0.02\nsamples = 9\nvalue = 12.235'),
Text(0.16857188858476896, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 11.977'),
Text(0.16921590726131058, 0.03125, 'squared_error = 0.002\nsamples = 7\nvalue = 12.309'),
Text(0.17018193527612302, 0.09375, 'X[47] <= 0.493\nsquared_error = 0.077\nsamples = 7\nvalue = 11.896'),
Text(0.1698599259378522, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 11.513'),
Text(0.1705039446143938, 0.03125, 'squared_error = 0.026\nsamples = 5\nvalue = 12.049'),
Text(0.17259700531315408, 0.21875, 'X[0] <= 16500.0\nsquared_error = 0.066\nsamples = 15\nvalue = 11.887'),
Text(0.17179198196747705, 0.15625, 'X[46] <= 0.916\nsquared_error = 0.029\nsamples = 11\nvalue = 12.006'),
Text(0.17146997262920624, 0.09375, 'X[56] <= 0.445\nsquared_error = 0.013\nsamples = 10\nvalue = 11.964'),
Text(0.17114796329093543, 0.03125, 'squared_error = 0.003\nsamples = 4\nvalue = 11.857'),
Text(0.17179198196747705, 0.03125, 'squared_error = 0.006\nsamples = 6\nvalue = 12.036'),
Text(0.17211399130574787, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 12.429'),
Text(0.17340202865883111, 0.15625, 'X[44] <= 0.502\nsquared_error = 0.019\nsamples = 4\nvalue = 11.557'),
Text(0.1727580099822895, 0.09375, 'X[17] <= 1.5\nsquared_error = 0.007\nsamples = 2\nvalue = 11.432'),
Text(0.17243600064401868, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.513'),
Text(0.1730800193205603, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.35'),
Text(0.17404604733537274, 0.09375, 'X[21] <= 1.5\nsquared_error = 0.0\nsamples = 2\nvalue = 11.683'),
Text(0.17372403799710193, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.67'),
Text(0.17436805667364352, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.695'),
Text(0.176139108034133, 0.34375, 'X[0] <= 7275.0\nsquared_error = 0.274\nsamples = 7\nvalue = 11.405'),
Text(0.17501207535018515, 0.28125, 'X[17] <= 1.5\nsquared_error = 0.072\nsamples = 4\nvalue = 10.993'),
Text(0.17436805667364352, 0.21875, 'X[55] <= 0.66\nsquared_error = 0.006\nsamples = 2\nvalue = 11.231'),
Text(0.17404604733537274, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.156'),
Text(0.17469006601191434, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.306'),
Text(0.17565609402672677, 0.21875, 'X[62] <= 0.215\nsquared_error = 0.025\nsamples = 2\nvalue = 10.756'),
Text(0.17533408468845596, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.915'),
Text(0.17597810336499758, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 10.597'),
Text(0.17726614071808083, 0.28125, 'X[49] <= 0.531\nsquared_error = 0.016\nsamples = 3\nvalue = 11.954'),
Text(0.17694413137981002, 0.21875, 'X[55] <= 0.62\nsquared_error = 0.0\nsamples = 2\nvalue = 12.044'),
Text(0.1766221220415392, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 12.044'),
Text(0.17726614071808083, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 12.044'),
Text(0.17758815005635165, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.775'),
Text(0.17710513604894543, 0.53125, 'X[50] <= 0.287\nsquared_error = 0.448\nsamples = 4\nvalue = 10.742'),
Text(0.17678312671067462, 0.46875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.752'),
Text(0.17742714538721624, 0.46875, 'X[41] <= 0.5\nsquared_error = 0.144\nsamples = 3\nvalue = 10.405'),
Text(0.17710513604894543, 0.40625, 'X[1] <= 860.0\nsquared_error = 0.027\nsamples = 2\nvalue = 10.656'),
Text(0.17678312671067462, 0.34375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.82'),
Text(0.17742714538721624, 0.34375, 'squared_error = -0.0\nsamples = 1\nvalue = 10.491'),
Text(0.17774915472548705, 0.40625, 'squared_error = 0.0\nsamples = 1\nvalue = 9.903'),
Text(0.1827528779584608, 0.65625, 'X[57] <= 0.999\nsquared_error = 0.491\nsamples = 1467\nvalue = 11.352'),
Text(0.18243086862018998, 0.59375, 'X[54] <= 0.001\nsquared_error = 0.465\nsamples = 1466\nvalue = 11.356'),
Text(0.17863468040573177, 0.53125, 'X[46] <= 0.496\nsquared_error = 9.56\nsamples = 2\nvalue = 8.198'),
Text(0.17831267106746096, 0.46875, 'squared_error = 0.0\nsamples = 1\nvalue = 5.106'),
Text(0.17895668974400258, 0.46875, 'squared_error = 0.0\nsamples = 1\nvalue = 11.29'),
Text(0.1862270568346482, 0.53125, 'X[1] <= 512.5\nsquared_error = 0.438\nsamples = 1464\nvalue = 11.36'),
Text(0.1796007084205442, 0.46875, 'X[45] <= 0.977\nsquared_error = 9.075\nsamples = 13\nvalue = 10.277'),
Text(0.1792786990822734, 0.40625, 'X[1] <= 122.0\nsquared_error = 0.297\nsamples = 12\nvalue = 11.133'),
Text(0.17823216873289324, 0.34375, 'X[1] <= 99.5\nsquared_error = 0.109\nsamples = 2\nvalue = 12.098'),
Text(0.17791015939462243, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.429'),
Text(0.17855417807116405, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.768'),
Text(0.18032522943165352, 0.34375, 'X[56] <= 0.449\nsquared_error = 0.111\nsamples = 10\nvalue = 10.94'),
Text(0.17919819674770568, 0.28125, 'X[58] <= 0.595\nsquared_error = 0.028\nsamples = 7\nvalue = 11.133'),
Text(0.17855417807116405, 0.21875, 'X[52] <= 0.519\nsquared_error = 0.001\nsamples = 3\nvalue = 11.318'),
Text(0.17823216873289324, 0.15625, 'X[47] <= 0.502\nsquared_error = 0.0\nsamples = 2\nvalue = 11.302'),
Text(0.17791015939462243, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.314'),
Text(0.17855417807116405, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.29'),
Text(0.17887618740943487, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 11.35'),
Text(0.1798422154242473, 0.21875, 'X[27] <= 0.5\nsquared_error = 0.004\nsamples = 4\nvalue = 10.993'),
Text(0.1795202060859765, 0.15625, 'X[60] <= 0.421\nsquared_error = 0.001\nsamples = 3\nvalue = 10.964'),
Text(0.17919819674770568, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.915'),
Text(0.1798422154242473, 0.09375, 'X[46] <= 0.574\nsquared_error = 0.0\nsamples = 2\nvalue = 10.988'),
Text(0.1795202060859765, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.99'),
Text(0.18016422476251812, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 10.985'),
Text(0.18016422476251812, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.082'),
Text(0.18145226211560136, 0.28125, 'X[46] <= 0.713\nsquared_error = 0.017\nsamples = 3\nvalue = 10.492'),
Text(0.18113025277733055, 0.21875, 'X[58] <= 0.406\nsquared_error = 0.0\nsamples = 2\nvalue = 10.584'),
Text(0.18080824343905974, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.597'),
Text(0.18145226211560136, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 10.571'),
Text(0.18177427145387215, 0.21875, 'squared_error = -0.0\nsamples = 1\nvalue = 10.309'),
Text(0.179922717758815, 0.40625, 'squared_error = 0.0\nsamples = 1\nvalue = 0.0'),
Text(0.19285340524875222, 0.46875, 'X[6] <= 1.5\nsquared_error = 0.35\nsamples = 1451\nvalue = 11.37'),
Text(0.18630252777330542, 0.40625, 'X[43] <= 0.004\nsquared_error = 0.342\nsamples = 603\nvalue = 11.246'),
Text(0.18402833682176784, 0.34375, 'X[58] <= 0.356\nsquared_error = 1.332\nsamples = 2\nvalue = 13.072'),
Text(0.18370632748349702, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.918'),
Text(0.18435034616003865, 0.28125, 'squared_error = -0.0\nsamples = 1\nvalue = 14.226'),
Text(0.18857671872484302, 0.34375, 'X[29] <= 0.5\nsquared_error = 0.328\nsamples = 601\nvalue = 11.239'),
Text(0.18499436483658027, 0.28125, 'X[54] <= 0.64\nsquared_error = 0.357\nsamples = 403\nvalue = 11.181'),
Text(0.18290130413782, 0.21875, 'X[62] <= 0.02\nsquared_error = 0.315\nsamples = 253\nvalue = 11.281'),
Text(0.18209628079214296, 0.15625, 'X[53] <= 0.751\nsquared_error = 2.213\nsamples = 2\nvalue = 10.005'),
Text(0.18177427145387215, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 11.493'),
Text(0.18241829013041377, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 8.517'),
Text(0.18370632748349702, 0.15625, 'X[46] <= 0.386\nsquared_error = 0.287\nsamples = 251\nvalue = 11.292'),
Text(0.1830623088069554, 0.09375, 'X[58] <= 0.068\nsquared_error = 0.284\nsamples = 98\nvalue = 11.414'),
Text(0.18274029946868459, 0.03125, 'squared_error = 0.265\nsamples = 2\nvalue = 9.725'),
Text(0.1833843181452262, 0.03125, 'squared_error = 0.224\nsamples = 96\nvalue = 11.449'),
Text(0.18435034616003865, 0.09375, 'X[57] <= 0.016\nsquared_error = 0.273\nsamples = 153\nvalue = 11.213'),
Text(0.18402833682176784, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.788'),
Text(0.18467235549830946, 0.03125, 'squared_error = 0.258\nsamples = 152\nvalue = 11.203'),
Text(0.18708742553534052, 0.21875, 'X[44] <= 0.992\nsquared_error = 0.381\nsamples = 150\nvalue = 11.011'),
Text(0.1862824021896635, 0.15625, 'X[59] <= 0.101\nsquared_error = 0.334\nsamples = 148\nvalue = 11.033'),
Text(0.18563838351312187, 0.09375, 'X[56] <= 0.228\nsquared_error = 0.443\nsamples = 7\nvalue = 10.326'),
Text(0.18531637417485108, 0.03125, 'squared_error = 0.103\nsamples = 4\nvalue = 9.815'),
Text(0.18596039285139268, 0.03125, 'squared_error = 0.086\nsamples = 3\nvalue = 11.006'),
Text(0.18692642086620512, 0.09375, 'X[46] <= 0.73\nsquared_error = 0.302\nsamples = 141\nvalue = 11.068'),
Text(0.1866044115279343, 0.03125, 'squared_error = 0.267\nsamples = 100\nvalue = 11.182'),
Text(0.18724843020447593, 0.03125, 'squared_error = 0.281\nsamples = 41\nvalue = 10.791'),
Text(0.18789244888101755, 0.15625, 'X[43] <= 0.454\nsquared_error = 1.176\nsamples = 2\nvalue = 9.379'),
Text(0.18757043954274674, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.463'),
Text(0.18821445821928837, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 8.294'),
Text(0.19215907261310577, 0.28125, 'X[0] <= 1950.0\nsquared_error = 0.247\nsamples = 198\nvalue = 11.359'),
Text(0.19030751891804862, 0.21875, 'X[0] <= 1775.0\nsquared_error = 0.3\nsamples = 17\nvalue = 11.728'),
Text(0.1895024955723716, 0.15625, 'X[1] <= 1575.0\nsquared_error = 0.157\nsamples = 15\nvalue = 11.581'),
Text(0.18885847689583, 0.09375, 'X[1] <= 1250.0\nsquared_error = 0.014\nsamples = 5\nvalue = 11.181'),
Text(0.18853646755755918, 0.03125, 'squared_error = 0.0\nsamples = 3\nvalue = 11.273'),
Text(0.18918048623410078, 0.03125, 'squared_error = 0.002\nsamples = 2\nvalue = 11.042'),
Text(0.1901465142489132, 0.09375, 'X[55] <= 0.629\nsquared_error = 0.109\nsamples = 10\nvalue = 11.782'),
Text(0.1898245049106424, 0.03125, 'squared_error = 0.07\nsamples = 7\nvalue = 11.622'),
Text(0.19046852358718402, 0.03125, 'squared_error = 0.002\nsamples = 3\nvalue = 12.154'),
Text(0.19111254226372565, 0.15625, 'X[32] <= 0.5\nsquared_error = 0.004\nsamples = 2\nvalue = 12.826'),
Text(0.19079053292545484, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.887'),
Text(0.19143455160199646, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.766'),
Text(0.19401062630816293, 0.21875, 'X[50] <= 0.503\nsquared_error = 0.228\nsamples = 181\nvalue = 11.325'),
Text(0.1927225889550797, 0.15625, 'X[50] <= 0.465\nsquared_error = 0.166\nsamples = 87\nvalue = 11.207'),
Text(0.19207857027853809, 0.09375, 'X[46] <= 0.004\nsquared_error = 0.129\nsamples = 81\nvalue = 11.254'),
Text(0.19175656094026727, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.405'),
Text(0.1924005796168089, 0.03125, 'squared_error = 0.114\nsamples = 80\nvalue = 11.24'),
Text(0.1933666076316213, 0.09375, 'X[54] <= 0.195\nsquared_error = 0.248\nsamples = 6\nvalue = 10.579'),
Text(0.1930445982933505, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 9.616'),
Text(0.19368861696989212, 0.03125, 'squared_error = 0.075\nsamples = 5\nvalue = 10.772'),
Text(0.19529866366124618, 0.15625, 'X[48] <= 0.926\nsquared_error = 0.261\nsamples = 94\nvalue = 11.433'),
Text(0.19465464498470456, 0.09375, 'X[60] <= 0.247\nsquared_error = 0.24\nsamples = 91\nvalue = 11.404'),
Text(0.19433263564643374, 0.03125, 'squared_error = 0.19\nsamples = 24\nvalue = 11.151'),
Text(0.19497665432297537, 0.03125, 'squared_error = 0.227\nsamples = 67\nvalue = 11.495'),
Text(0.1959426823377878, 0.09375, 'X[47] <= 0.49\nsquared_error = 0.103\nsamples = 3\nvalue = 12.313'),
Text(0.195620672999517, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.766'),
Text(0.19626469167605862, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 12.087'),
Text(0.199404282724199, 0.40625, 'X[50] <= 0.005\nsquared_error = 0.338\nsamples = 848\nvalue = 11.458'),
Text(0.19739172436000643, 0.34375, 'X[45] <= 0.431\nsquared_error = 8.712\nsamples = 4\nvalue = 9.713'),
Text(0.19706971502173562, 0.28125, 'X[43] <= 0.513\nsquared_error = 0.019\nsamples = 3\nvalue = 11.416'),
Text(0.1967477056834648, 0.21875, 'X[0] <= 28600.0\nsquared_error = 0.001\nsamples = 2\nvalue = 11.32'),
Text(0.19642569634519402, 0.15625, 'squared_error = 0.0\nsamples = 1\nvalue = 11.29'),
Text(0.19706971502173562, 0.15625, 'squared_error = -0.0\nsamples = 1\nvalue = 11.35'),
Text(0.19739172436000643, 0.21875, 'squared_error = -0.0\nsamples = 1\nvalue = 11.608'),
Text(0.19771373369827724, 0.28125, 'squared_error = -0.0\nsamples = 1\nvalue = 4.605'),
Text(0.20141684108839156, 0.34375, 'X[9] <= 1.5\nsquared_error = 0.283\nsamples = 844\nvalue = 11.467'),
Text(0.19835775237481887, 0.28125, 'X[4] <= 1.5\nsquared_error = 0.463\nsamples = 60\nvalue = 11.87'),
Text(0.19803574303654806, 0.21875, 'squared_error = 0.0\nsamples = 1\nvalue = 14.344'),
Text(0.19867976171308968, 0.21875, 'X[53] <= 0.938\nsquared_error = 0.366\nsamples = 59\nvalue = 11.828'),
Text(0.19787473836741265, 0.15625, 'X[61] <= 0.122\nsquared_error = 0.248\nsamples = 57\nvalue = 11.767'),
Text(0.19723071969087103, 0.09375, 'X[52] <= 0.503\nsquared_error = 0.197\nsamples = 4\nvalue = 11.048'),
Text(0.1969087103526002, 0.03125, 'squared_error = 0.027\nsamples = 3\nvalue = 10.806'),
Text(0.19755272902914184, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.775'),
Text(0.19851875704395427, 0.09375, 'X[60] <= 0.696\nsquared_error = 0.21\nsamples = 53\nvalue = 11.822'),
Text(0.19819674770568346, 0.03125, 'squared_error = 0.15\nsamples = 38\nvalue = 11.957'),
Text(0.1988407663822251, 0.03125, 'squared_error = 0.201\nsamples = 15\nvalue = 11.48'),
Text(0.1994847850587667, 0.15625, 'X[53] <= 0.968\nsquared_error = 0.623\nsamples = 2\nvalue = 13.555'),
Text(0.1991627757204959, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 14.344'),
Text(0.19980679439703752, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 12.766'),
Text(0.20447592980196425, 0.28125, 'X[0] <= 80520.0\nsquared_error = 0.256\nsamples = 784\nvalue = 11.436'),
Text(0.202382869103204, 0.21875, 'X[4] <= 2.5\nsquared_error = 0.236\nsamples = 701\nvalue = 11.404'),
Text(0.20109483175012074, 0.15625, 'X[54] <= 0.839\nsquared_error = 0.261\nsamples = 243\nvalue = 11.278'),
Text(0.20045081307357912, 0.09375, 'X[1] <= 1850.0\nsquared_error = 0.196\nsamples = 202\nvalue = 11.334'),
Text(0.20012880373530834, 0.03125, 'squared_error = 0.192\nsamples = 157\nvalue = 11.39'),
Text(0.20077282241184993, 0.03125, 'squared_error = 0.158\nsamples = 45\nvalue = 11.138'),
Text(0.20173885042666237, 0.09375, 'X[47] <= 0.469\nsquared_error = 0.493\nsamples = 41\nvalue = 11.002'),
Text(0.20141684108839156, 0.03125, 'squared_error = 0.61\nsamples = 16\nvalue = 10.514'),
Text(0.20206085976493318, 0.03125, 'squared_error = 0.169\nsamples = 25\nvalue = 11.314'),
Text(0.20367090645628724, 0.15625, 'X[1] <= 958.5\nsquared_error = 0.209\nsamples = 458\nvalue = 11.472'),
Text(0.20302688777974562, 0.09375, 'X[0] <= 3700.0\nsquared_error = 0.176\nsamples = 27\nvalue = 11.098'),
Text(0.2027048784414748, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.206'),
Text(0.20334889711801643, 0.03125, 'squared_error = 0.133\nsamples = 26\nvalue = 11.055'),
Text(0.20431492513282884, 0.09375, 'X[48] <= 0.957\nsquared_error = 0.202\nsamples = 431\nvalue = 11.495'),
Text(0.20399291579455806, 0.03125, 'squared_error = 0.193\nsamples = 413\nvalue = 11.479'),
Text(0.20463693447109965, 0.03125, 'squared_error = 0.248\nsamples = 18\nvalue = 11.874'),
Text(0.20656899050072453, 0.21875, 'X[50] <= 0.928\nsquared_error = 0.351\nsamples = 83\nvalue = 11.702'),
Text(0.2059249718241829, 0.15625, 'X[26] <= 1.5\nsquared_error = 0.293\nsamples = 79\nvalue = 11.654'),
Text(0.2056029624859121, 0.09375, 'X[61] <= 0.951\nsquared_error = 0.255\nsamples = 78\nvalue = 11.631'),
Text(0.20528095314764128, 0.03125, 'squared_error = 0.231\nsamples = 75\nvalue = 11.664'),
Text(0.2059249718241829, 0.03125, 'squared_error = 0.121\nsamples = 3\nvalue = 10.798'),
Text(0.2062469811624537, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 13.459'),
Text(0.20721300917726615, 0.15625, 'X[45] <= 0.841\nsquared_error = 0.54\nsamples = 4\nvalue = 12.654'),
Text(0.20689099983899534, 0.09375, 'X[48] <= 0.393\nsquared_error = 0.063\nsamples = 3\nvalue = 12.248'),
Text(0.20656899050072453, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.918'),
Text(0.20721300917726615, 0.03125, 'squared_error = 0.012\nsamples = 2\nvalue = 12.413'),
Text(0.20753501851553696, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 13.87'),
Text(0.1830748872967316, 0.59375, 'squared_error = -0.0\nsamples = 1\nvalue = 5.106'),
Text(0.3660186438375463, 0.78125, 'X[1] <= 1581.0\nsquared_error = 0.509\nsamples = 8801\nvalue = 11.858'),
Text(0.2880914405892771, 0.71875, 'X[19] <= 1.5\nsquared_error = 0.59\nsamples = 2586\nvalue = 11.65'),
Text(0.2612602640476574, 0.65625, 'X[29] <= 0.5\nsquared_error = 0.538\nsamples = 2247\nvalue = 11.685'),
Text(0.2408705321204315, 0.59375, 'X[21] <= 1.5\nsquared_error = 0.557\nsamples = 1847\nvalue = 11.652'),
Text(0.22988951054580584, 0.53125, 'X[0] <= 301467.0\nsquared_error = 0.534\nsamples = 1817\nvalue = 11.662'),
Text(0.21970093382708097, 0.46875, 'X[0] <= 1537.5\nsquared_error = 0.53\nsamples = 1788\nvalue = 11.653'),
Text(0.21027209789083884, 0.40625, 'X[44] <= 0.033\nsquared_error = 2.919\nsamples = 53\nvalue = 11.306'),
Text(0.2096280792142972, 0.34375, 'X[56] <= 0.728\nsquared_error = 31.115\nsamples = 2\nvalue = 5.578'),
Text(0.2093060698760264, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 0.0'),
Text(0.20995008855256803, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.156'),
Text(0.21091611656738046, 0.34375, 'X[47] <= 0.036\nsquared_error = 0.476\nsamples = 51\nvalue = 11.531'),
Text(0.21059410722910965, 0.28125, 'squared_error = 0.0\nsamples = 1\nvalue = 8.517'),
Text(0.21123812590565128, 0.28125, 'X[2] <= 1965.0\nsquared_error = 0.301\nsamples = 50\nvalue = 11.591'),
Text(0.209145065206891, 0.21875, 'X[59] <= 0.558\nsquared_error = 0.801\nsamples = 7\nvalue = 11.013'),
Text(0.20850104653034937, 0.15625, 'X[61] <= 0.223\nsquared_error = 0.302\nsamples = 2\nvalue = 9.76'),
Text(0.20817903719207856, 0.09375, 'squared_error = 0.0\nsamples = 1\nvalue = 10.309'),
Text(0.20882305586862018, 0.09375, 'squared_error = -0.0\nsamples = 1\nvalue = 9.21'),
Text(0.20978908388343262, 0.15625, 'X[62] <= 0.133\nsquared_error = 0.121\nsamples = 5\nvalue = 11.515'),
Text(0.2094670745451618, 0.09375, 'squared_error = 0.0\nsamples = 2\nvalue = 11.918'),
Text(0.21011109322170343, 0.09375, 'X[0] <= 1300.0\nsquared_error = 0.02\nsamples = 3\nvalue = 11.246'),
Text(0.20978908388343262, 0.03125, 'squared_error = 0.005\nsamples = 2\nvalue = 11.154'),
Text(0.21043310255997424, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.43'),
Text(0.21333118660441153, 0.21875, 'X[53] <= 0.309\nsquared_error = 0.156\nsamples = 43\nvalue = 11.685'),
Text(0.21204314925132828, 0.15625, 'X[59] <= 0.162\nsquared_error = 0.1\nsamples = 6\nvalue = 11.21'),
Text(0.21139913057478668, 0.09375, 'X[48] <= 0.799\nsquared_error = 0.021\nsamples = 3\nvalue = 11.489'),
Text(0.21107712123651587, 0.03125, 'squared_error = 0.002\nsamples = 2\nvalue = 11.39'),
Text(0.21172113991305747, 0.03125, 'squared_error = -0.0\nsamples = 1\nvalue = 11.687'),
Text(0.2126871679278699, 0.09375, 'X[60] <= 0.217\nsquared_error = 0.025\nsamples = 3\nvalue = 10.932'),
Text(0.2123651585895991, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 11.156'),
Text(0.21300917726614071, 0.03125, 'squared_error = 0.0\nsamples = 2\nvalue = 10.82'),
Text(0.21461922395749478, 0.15625, 'X[47] <= 0.635\nsquared_error = 0.122\nsamples = 37\nvalue = 11.762'),
Text(0.21397520528095315, 0.09375, 'X[27] <= 0.5\nsquared_error = 0.083\nsamples = 19\nvalue = 11.959'),
Text(0.21365319594268234, 0.03125, 'squared_error = 0.062\nsamples = 16\nvalue = 11.885'),
Text(0.21429721461922396, 0.03125, 'squared_error = 0.011\nsamples = 3\nvalue = 12.355'),
Text(0.2152632426340364, 0.09375, 'X[61] <= 0.947\nsquared_error = 0.079\nsamples = 18\nvalue = 11.555'),
Text(0.2149412332957656, 0.03125, 'squared_error = 0.049\nsamples = 17\nvalue = 11.511'),
Text(0.21558525197230718, 0.03125, 'squared_error = 0.0\nsamples = 1\nvalue = 12.301'),
Text(0.22912976976332314, 0.40625, 'X[28] <= 0.5\nsquared_error = 0.453\nsamples = 1735\nvalue = 11.664'),
Text(0.22311222025438737, 0.34375, 'X[2] <= 1935.0\nsquared_error = 0.478\nsamples = 1559\nvalue = 11.645'),
Text(0.22025438737723393, 0.28125, 'X[8] <= 3.5\nsquared_error = 0.273\nsamples = 76\nvalue = 11.921'),
Text(0.2184833360167445, 0.21875, 'X[51] <= 0.689\nsquared_error = 0.249\nsamples = 69\nvalue = 11.853'),
Text(0.21719529866366125, 0.15625, 'X[0] <= 4856.0\nsquared_error = 0.186\nsamples = 39\nvalue = 12.018'),
...]

To reduce the complexity of the tree, we prune the tree: we collapse its leaves, permitting bias to increase but forcing variance to decrease until the desired trade-off is achieved. In rpart, this is done by considering a modified loss function that takes into account the number of terminal nodes (i.e., the number of regions in which the original data was partitioned). Somewhat heuristically, if we denote tree predictions by \(T(x)\) and its number of terminal nodes by \(|T|\), the modified regression problem can be written as:
The complexity of the tree is controlled by the scalar parameter \(c_p\), denoted as ccp_alpha in sklearn.tree.DecisionTreeRegressor. For each value of \(c_p\), we find the subtree that solves (2.4). Large values of \(c_p\) lead to aggressively pruned trees, which have more bias and less variance. Small values of \(c_p\) allow for deeper trees whose predictions can vary more wildly.
import itertools
path = dt.cost_complexity_pruning_path(x_train,y_train)
alphas_dt = pd.Series(path['ccp_alphas'], name = "alphas").unique()
# A function with a manual cross validation
#This function can replicate cp_table that R's rplot package creates to get the best complexity parameter
#This function can be used to prune the tree but it is a lar process, so if you have the computational power, you can use this function
'''
def run_cross_validation_on_trees2(X, y, tree_ccp, nfold=10):
cp_table_error = []
cp_table_std = []
cp_table_rel_error = []
cp_table_size = []
# Num ob observations
nobs = y.shape[0]
# Define folds indices
list_1 = [*range(0, nfold, 1)]*nobs
sample = np.random.choice(nobs,nobs, replace=False).tolist()
foldid = [list_1[index] for index in sample]
# Create split function(similar to R)
def split(x, f):
count = max(f) + 1
return tuple( list(itertools.compress(x, (el == i for el in f))) for i in range(count) )
# Split observation indices into folds
list_2 = [*range(0, nobs, 1)]
I = split(list_2, foldid)
for i in tree_ccp:
cv_error_list = []
cv_rel_error_list = []
dtree = DecisionTreeRegressor( ccp_alpha= i, random_state = 0)
# loop to save results
for b in range(0,len(I)):
# Split data - index to keep are in mask as booleans
include_idx = set(I[b]) #Here should go I[b] Set is more efficient, but doesn't reorder your elements if that is desireable
mask = np.array([(a in include_idx) for a in range(len(y))])
dtree.fit(X[~mask], Y[~mask])
pred = dtree.predict(X[mask])
xerror_fold = np.mean(np.power(pred - y[mask],2))
rel_error_fold = 1- r2_score(y[mask], pred)
cv_error_list.append(xerror_fold)
cv_rel_error_list.append(rel_error_fold)
rel_error = np.mean(cv_rel_error_list)
xerror = np.mean(cv_error_list)
xstd = np.std(cv_error_list)
cp_table_rel_error.append(rel_error)
cp_table_error.append(xerror)
cp_table_std.append(xstd)
cp_table_size.append(dtree.tree_.node_count)
cp_table = pd.DataFrame([pd.Series(tree_ccp, name = "cp"), pd.Series(cp_table_size, name = "size")
, pd.Series(cp_table_rel_error, name = "rel error"),
pd.Series(cp_table_error, name = "xerror"),
pd.Series(cp_table_std, name = "xstd")]).T
return cp_table
'''
#Here we create a loop to get an arrange with all Mean Squared Errors for each cp_alpha
from sklearn.metrics import mean_squared_error
mse_gini = []
cp_table_size = []
for i in alphas_dt:
dtree = DecisionTreeRegressor( ccp_alpha=i, random_state = 0)
dtree.fit(x_train, y_train)
pred = dtree.predict(x_test)
mse_gini.append(mean_squared_error(y_test, pred))
cp_table_size.append(dtree.tree_.node_count)
d2 = pd.DataFrame({'acc_gini':pd.Series(mse_gini),'ccp_alphas':pd.Series(alphas_dt)})
#plt.style.context("dark_background")
# visualizing changes in parameters
plt.figure(figsize=(18,5), facecolor = "white")
plt.plot('ccp_alphas','acc_gini', data=d2, label='mse', marker="o", color='black')
#plt.gca().invert_xaxis()
#plt.xticks(np.arange(0, 0.15, step=0.01)) # Set label locations.
#plt.yticks(np.arange(0.5, 1.5, step=0.1)) # Set label locations.
plt.tick_params( axis='x', labelsize=15, length=0, labelrotation=0)
plt.tick_params( axis='y', labelsize=15, length=0, labelrotation=0)
plt.grid()
plt.xlabel('cp', fontsize = 15)
plt.ylabel('mse', fontsize = 15)
plt.legend()
<matplotlib.legend.Legend at 0x229901244c0>
#It is a function to get the best max_depth parametor with cross-validation
def prune_max_depth(X, y, nfold=10):
cv_mean_mse = []
max_depth = []
# Num ob observations
nobs = y.shape[0]
# Define folds indices
list_1 = [*range(0, nfold, 1)]*nobs
sample = np.random.choice(nobs,nobs, replace=False).tolist()
foldid = [list_1[index] for index in sample]
# Create split function(similar to R)
def split(x, f):
count = max(f) + 1
return tuple( list(itertools.compress(x, (el == i for el in f))) for i in range(count) )
# Split observation indices into folds
list_2 = [*range(0, nobs, 1)]
I = split(list_2, foldid)
for i in range(1,20):
max_depth.append(i)
mse_depth = []
dtree = DecisionTreeRegressor( max_depth=i, random_state = 0)
for b in range(0,len(I)):
# Split data - index to keep are in mask as booleans
include_idx = set(I[b]) #Here should go I[b] Set is more efficient, but doesn't reorder your elements if that is desireable
mask = np.array([(a in include_idx) for a in range(len(y))])
dtree.fit(X[~mask], y[~mask])
pred = dtree.predict(X[mask])
mse_depth.append(mean_squared_error(y[mask],pred))
mse = np.mean(mse_depth)
cv_mean_mse.append(mse)
d1 = pd.DataFrame({'acc_depth':pd.Series(cv_mean_mse),'max_depth':pd.Series(max_depth)})
return d1
d1 = prune_max_depth(x_train, y_train)
# visualizing changes in parameters
plt.figure(figsize=(18,5))
plt.plot('max_depth','acc_depth', data=d1, label='mse', marker="o")
plt.xticks(np.arange(1,20))
plt.xlabel('max_depth')
plt.ylabel('mse')
plt.legend()
<matplotlib.legend.Legend at 0x229926aff40>
The following code retrieves the optimal parameter and prunes the tree. Here, instead of choosing the parameter that minimizes the mean-squared-error, we’re following another common heuristic: we will choose the most regularized model whose error is within one standard error of the minimum error.
# We get the best parameters
best_max_depth = d1[d1["acc_depth"] == np.min(d1["acc_depth"])].iloc[0,1]
best_ccp = d2[d2["acc_gini"] == np.min(d2["acc_gini"])].iloc[0,1]
# Prune the tree
dt = DecisionTreeRegressor(max_depth=best_max_depth , ccp_alpha= best_ccp , random_state=0)
tree1 = dt.fit(x_train,y_train)
Plotting the pruned tree. See also the package rpart.plot for more advanced plotting capabilities.
from sklearn import tree
plt.figure(figsize=(25,16))
tree.plot_tree(dt, filled=True, rounded=True, feature_names = XX.columns)
[Text(0.65, 0.9, 'NUNIT2 <= 3.5\nsquared_error = 1.01\nsamples = 20108\nvalue = 11.812'),
Text(0.4, 0.7, 'UNITSF <= 2436.5\nsquared_error = 0.823\nsamples = 19378\nvalue = 11.884'),
Text(0.2, 0.5, 'BATHS <= 1.5\nsquared_error = 0.698\nsamples = 13909\nvalue = 11.68'),
Text(0.1, 0.3, 'KITCH <= 0.5\nsquared_error = 0.782\nsamples = 5112\nvalue = 11.38'),
Text(0.05, 0.1, 'squared_error = 0.0\nsamples = 1\nvalue = 0.0'),
Text(0.15, 0.1, 'squared_error = 0.757\nsamples = 5111\nvalue = 11.382'),
Text(0.3, 0.3, 'UNITSF <= 1692.0\nsquared_error = 0.567\nsamples = 8797\nvalue = 11.854'),
Text(0.25, 0.1, 'squared_error = 0.533\nsamples = 3227\nvalue = 11.684'),
Text(0.35, 0.1, 'squared_error = 0.56\nsamples = 5570\nvalue = 11.953'),
Text(0.6, 0.5, 'BATHS <= 2.5\nsquared_error = 0.768\nsamples = 5469\nvalue = 12.402'),
Text(0.5, 0.3, 'BATHS <= 1.5\nsquared_error = 0.739\nsamples = 2839\nvalue = 12.156'),
Text(0.45, 0.1, 'squared_error = 1.112\nsamples = 328\nvalue = 11.625'),
Text(0.55, 0.1, 'squared_error = 0.649\nsamples = 2511\nvalue = 12.225'),
Text(0.7, 0.3, 'UNITSF <= 3999.0\nsquared_error = 0.664\nsamples = 2630\nvalue = 12.667'),
Text(0.65, 0.1, 'squared_error = 0.538\nsamples = 1645\nvalue = 12.495'),
Text(0.75, 0.1, 'squared_error = 0.742\nsamples = 985\nvalue = 12.954'),
Text(0.9, 0.7, 'MOBILTYP <= 1.5\nsquared_error = 2.186\nsamples = 730\nvalue = 9.901'),
Text(0.85, 0.5, 'UNITSF <= 15977.5\nsquared_error = 2.4\nsamples = 417\nvalue = 9.372'),
Text(0.8, 0.3, 'squared_error = 2.194\nsamples = 416\nvalue = 9.394'),
Text(0.9, 0.3, 'squared_error = -0.0\nsamples = 1\nvalue = 0.0'),
Text(0.95, 0.5, 'squared_error = 1.031\nsamples = 313\nvalue = 10.606')]
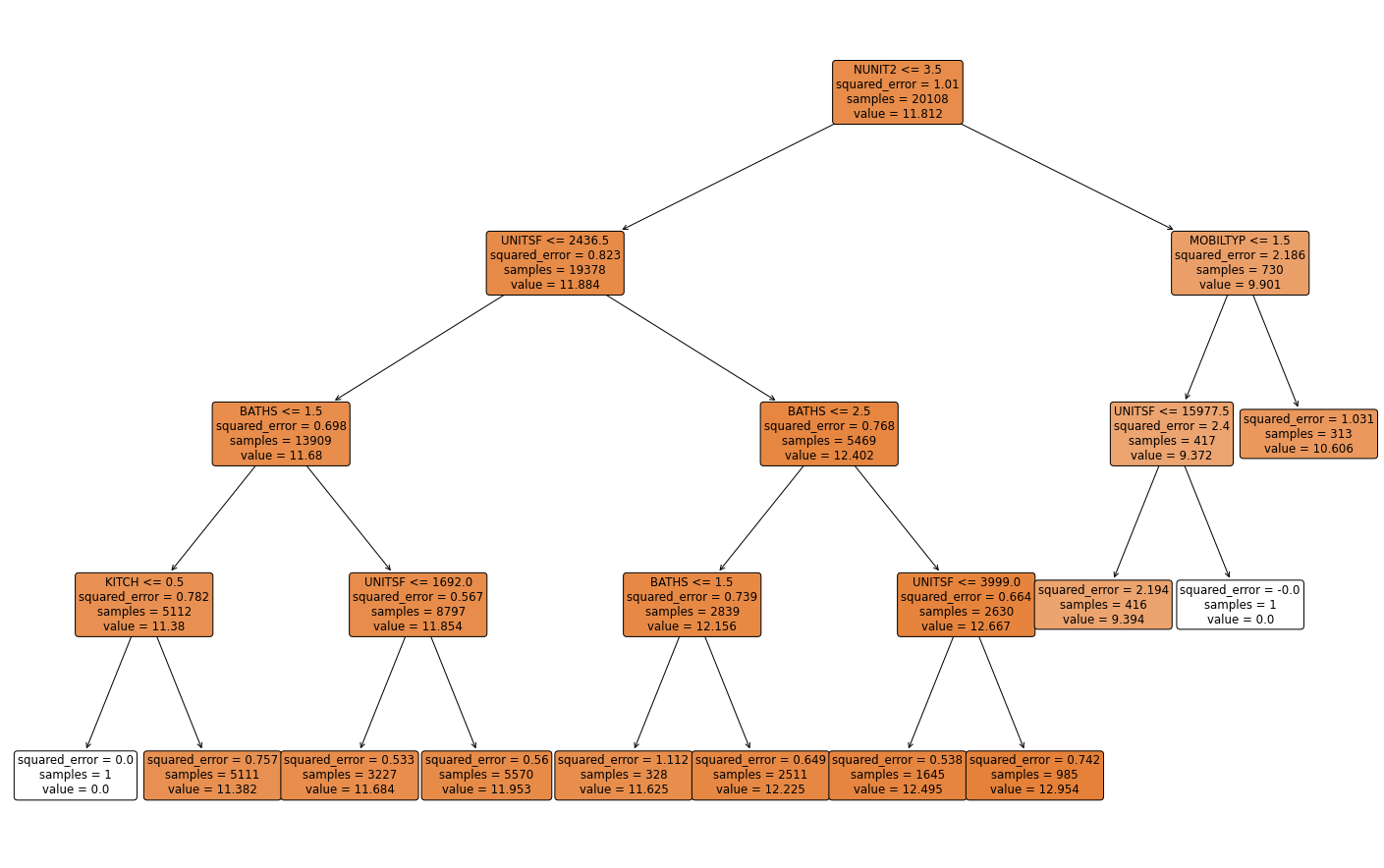
Finally, here’s how to extract predictions and mse estimates from the pruned tree.
y_pred = dt.predict(x_test)
mse = mean_squared_error(y_test, y_pred)
print("Tree MSE estimate:", mse)
Tree MSE estimate: 0.5442705453177679
It’s often said that trees are “interpretable.” To some extent, that’s true – we can look at the tree and clearly visualize the mapping from inputs to prediction. This can be important in settings in which conveying how one got to a prediction is important. For example, if a decision tree were to be used for credit scoring, it would be easy to explain to a client how their credit was scored.
Beyond that, however, there are several reasons for not interpreting the obtained decision tree further. First, even though a tree may have used a particular variable for a split, that does not mean that it’s indeed an important variable: if two covariates are highly correlated, the tree may split on one variable but not the other, and there’s no guarantee which variables are relevant in the underlying data-generating process.
Similar to what we did for Lasso above, we can estimate the average value of each covariate per leaf. Although results are noisier here because there are many leaves, we see somewhat similar trends in that houses with higher predictions are also correlated with more bedrooms, bathrooms and room sizes.
from pandas import Series
from simple_colors import *
import statsmodels.api as sm
import statsmodels.formula.api as smf
from scipy.stats import norm
y_pred
num_leaves = len(pd.Series(y_pred).unique())
categ = pd.Categorical(y_pred, categories= np.sort(pd.unique(y_pred)))
leaf = categ.rename_categories(np.arange(1,len(categ.categories)+1))
data1 = pd.DataFrame(data=x_test, columns= covariates)
data1["leaf"] = leaf
for var_name in covariates:
form2 = var_name + " ~ " + "0" + "+" + "leaf"
ols = smf.ols(formula=form2, data=data1).fit(cov_type = 'HC2').summary2().tables[1].iloc[:, 0:2].T
print(red(var_name, 'bold'),ols, "\n")
LOT leaf[1] leaf[2] leaf[3] leaf[4] \
Coef. 76491.899559 129102.123280 35058.201371 59815.230609
Std.Err. 12405.242699 17921.335635 2134.642203 11159.843199
leaf[5] leaf[6] leaf[7] leaf[8] leaf[9]
Coef. 37474.451548 44275.523233 54379.653727 49666.380327 77444.878973
Std.Err. 2632.981719 2282.706417 3883.339922 4296.772925 7871.645357
UNITSF leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] \
Coef. 1253.436921 1919.370259 1564.492235 5085.737805 1368.844174
Std.Err. 43.006720 151.630637 12.265223 375.593742 5.763695
leaf[6] leaf[7] leaf[8] leaf[9]
Coef. 2087.609012 3608.566364 3138.982620 8380.256000
Std.Err. 5.101007 69.986674 14.813386 228.071867
BUILT leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] \
Coef. 1982.409326 1986.656000 1951.951955 1949.652439 1978.756254
Std.Err. 0.975004 1.125603 0.457493 1.686299 0.574931
leaf[6] leaf[7] leaf[8] leaf[9]
Coef. 1978.991221 1982.609091 1988.700535 1989.653333
Std.Err. 0.464422 0.662736 0.685155 1.091059
BATHS leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.538860 2.000000 0.997174 0.993902 2.028592 2.134197
Std.Err. 0.036718 0.027824 0.001152 0.006098 0.004457 0.007777
leaf[7] leaf[8] leaf[9]
Coef. 2.000000e+00 3.153743 3.634667
Std.Err. 2.545218e-16 0.014613 0.040049
BEDRMS leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] leaf[7] \
Coef. 2.430052 3.080000 2.72586 3.085366 2.934954 3.337793 3.620909
Std.Err. 0.044477 0.057474 0.01540 0.057637 0.015716 0.014112 0.020111
leaf[8] leaf[9]
Coef. 4.056150 4.389333
Std.Err. 0.025086 0.040948
DINING leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.202073 0.608000 0.487989 0.713415 0.469621 0.717391
Std.Err. 0.029896 0.050668 0.011054 0.037469 0.013947 0.010268
leaf[7] leaf[8] leaf[9]
Coef. 0.870000 0.921123 1.013333
Std.Err. 0.013806 0.014918 0.019791
METRO leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 6.367876 6.600000 4.587376 4.658537 5.609721 5.613294
Std.Err. 0.131099 0.129515 0.063162 0.226951 0.066153 0.050662
leaf[7] leaf[8] leaf[9]
Coef. 5.976364 6.164439 6.402667
Std.Err. 0.067004 0.074326 0.091031
CRACKS leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.922280 1.944000 1.922280 1.932927 1.954253 1.948997
Std.Err. 0.019322 0.020648 0.005812 0.019593 0.005588 0.004499
leaf[7] leaf[8] leaf[9]
Coef. 1.966364 1.967914 1.978667
Std.Err. 0.005438 0.006448 0.007472
REGION leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 2.766839 2.960000 2.471032 2.493902 2.869192 2.764214
Std.Err. 0.045438 0.058365 0.015533 0.051534 0.017560 0.013070
leaf[7] leaf[8] leaf[9]
Coef. 2.674545 2.879679 2.826667
Std.Err. 0.019998 0.022828 0.033958
METRO3 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.891192 2.040000 1.682525 1.646341 2.057898 1.996656
Std.Err. 0.022473 0.083008 0.021217 0.059137 0.040916 0.028187
leaf[7] leaf[8] leaf[9]
Coef. 2.001818 2.060160 2.176000
Std.Err. 0.035992 0.046038 0.073729
PHONE leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.601036 0.712000 0.672162 0.682927 0.711937 0.682274
Std.Err. 0.128542 0.142247 0.035345 0.127639 0.040607 0.032536
leaf[7] leaf[8] leaf[9]
Coef. 0.684545 0.744652 0.562667
Std.Err. 0.047985 0.052842 0.095394
KITCHEN leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] leaf[7] \
Coef. 1.005181 1.008 1.012718 1.006098 1.003574 1.004181 1.001818
Std.Err. 0.005181 0.008 0.002433 0.006098 0.001596 0.001320 0.001285
leaf[8] leaf[9]
Coef. 1.005348 1.000000e+00
Std.Err. 0.002668 1.033549e-16
MOBILTYP leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] \
Coef. 0.979275 2.000000e+00 -1.000000e+00 -1.000000e+00 -1.000000e+00
Std.Err. 0.014617 7.976078e-17 2.169102e-17 3.478375e-17 1.722204e-16
leaf[6] leaf[7] leaf[8] leaf[9]
Coef. -1.000000e+00 -1.000000e+00 -1.000000e+00 -1.000000e+00
Std.Err. 4.541240e-18 1.272609e-16 9.749025e-17 1.033349e-16
WINTEROVEN leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.932642 1.832000 1.943005 1.975610 1.972838 1.973244
Std.Err. 0.052497 0.112872 0.013459 0.012082 0.012155 0.009126
leaf[7] leaf[8] leaf[9]
Coef. 1.968182 1.998663 1.946667
Std.Err. 0.014886 0.001337 0.034084
WINTERKESP leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.880829 1.776000 1.940650 1.993902 1.964260 1.962375
Std.Err. 0.054548 0.114082 0.013496 0.006098 0.012389 0.009356
leaf[7] leaf[8] leaf[9]
Coef. 1.953636 1.994652 1.936000
Std.Err. 0.015290 0.002668 0.034452
WINTERELSP leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] leaf[7] \
Coef. 1.725389 1.6560 1.765897 1.817073 1.814868 1.832776 1.826364
Std.Err. 0.058875 0.1159 0.015502 0.030281 0.015387 0.011429 0.018003
leaf[8] leaf[9]
Coef. 1.822193 1.832000
Std.Err. 0.013989 0.037423
WINTERWOOD leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.948187 1.84000 1.962789 2.000000e+00 1.977841 1.977843
Std.Err. 0.051813 0.11268 0.013142 6.956750e-17 0.012014 0.009025
leaf[7] leaf[8] leaf[9]
Coef. 1.973636 1.998663 1.949333
Std.Err. 0.014728 0.001337 0.033990
WINTERNONE leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.243523 1.104000 1.190768 1.182927 1.163688 1.153010
Std.Err. 0.058209 0.111195 0.015119 0.030281 0.015059 0.011251
leaf[7] leaf[8] leaf[9]
Coef. 1.145455 1.183155 1.098667
Std.Err. 0.017512 0.014152 0.035560
NEWC leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. -8.844560 -8.600000 -8.962317 -9.000000e+00 -8.756969 -8.632107
Std.Err. 0.089275 0.175977 0.013301 1.391350e-16 0.041185 0.038497
leaf[7] leaf[8] leaf[9]
Coef. -8.663636 -8.358289 -8.200000
Std.Err. 0.054385 0.089662 0.140282
DISH leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.606218 1.224000 1.495525 1.341463 1.105790 1.084448
Std.Err. 0.035261 0.037441 0.010854 0.037142 0.008226 0.005687
leaf[7] leaf[8] leaf[9]
Coef. 1.046364 1.010695 1.005333
Std.Err. 0.006343 0.003764 0.003766
WASH leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.093264 1.040000 1.053227 1.024390 1.015011 1.007107
Std.Err. 0.020987 0.017598 0.004873 0.012082 0.003252 0.001718
leaf[7] leaf[8] leaf[9]
Coef. 1.003636 1.002674 1.002667
Std.Err. 0.001816 0.001889 0.002667
DRY leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.155440 1.040000 1.078662 1.060976 1.026447 1.010452
Std.Err. 0.026148 0.017598 0.005844 0.018742 0.004292 0.002080
leaf[7] leaf[8] leaf[9]
Coef. 1.003636 1.002674 1.005333
Std.Err. 0.001816 0.001889 0.003766
NUNIT2 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 4.000000e+00 4.000000e+00 1.163919 1.04878 1.230164 1.076505
Std.Err. 1.922963e-16 1.595216e-16 0.011039 0.02084 0.014687 0.006598
leaf[7] leaf[8] leaf[9]
Coef. 1.025455 1.030749 1.008000
Std.Err. 0.005701 0.007363 0.005956
BURNER leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. -5.803109 -5.816000 -5.914743 -6.000000e+00 -5.962116 -5.976589
Std.Err. 0.087316 0.105576 0.017701 3.478375e-16 0.014319 0.008838
leaf[7] leaf[8] leaf[9]
Coef. -5.98000 -5.989305 -5.981333
Std.Err. 0.01156 0.010695 0.018667
COOK leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.025907 1.024000 1.010834 1.000000e+00 1.005004 1.002926
Std.Err. 0.011465 0.013744 0.002247 3.478375e-17 0.001887 0.001105
leaf[7] leaf[8] leaf[9]
Coef. 1.002727 1.001337 1.002667
Std.Err. 0.001573 0.001337 0.002667
OVEN leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. -5.891192 -5.888000 -5.931700 -6.000000e+00 -5.979271 -5.979515
Std.Err. 0.062492 0.078876 0.015231 3.478375e-16 0.010372 0.007733
leaf[7] leaf[8] leaf[9]
Coef. -5.993636 -5.989305 -6.000000e+00
Std.Err. 0.006364 0.010695 2.758533e-16
REFR leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] leaf[7] \
Coef. 1.005181 1.008 1.006123 1.006098 1.002144 1.001672 1.000909
Std.Err. 0.005181 0.008 0.001694 0.006098 0.001237 0.000836 0.000909
leaf[8] leaf[9]
Coef. 1.004011 1.000000e+00
Std.Err. 0.002312 1.033446e-16
DENS leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] leaf[7] \
Coef. 0.0 0.144000 0.099859 0.189024 0.092924 0.195652 0.272727
Std.Err. 0.0 0.031529 0.006643 0.035210 0.007895 0.008492 0.014095
leaf[8] leaf[9]
Coef. 0.328877 0.464000
Std.Err. 0.018781 0.032404
FAMRM leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.005181 0.072000 0.115874 0.182927 0.105075 0.287625
Std.Err. 0.005181 0.025843 0.007012 0.030281 0.008447 0.009772
leaf[7] leaf[8] leaf[9]
Coef. 0.440909 0.537433 0.752000
Std.Err. 0.017569 0.022223 0.040841
HALFB leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.186528 0.096000 0.451248 0.676829 0.190136 0.408445
Std.Err. 0.071847 0.028791 0.011710 0.045717 0.010925 0.010709
leaf[7] leaf[8] leaf[9]
Coef. 0.813636 0.568182 0.91200
Std.Err. 0.015878 0.021217 0.03503
KITCH leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.000000e+00 1.008 1.002355 1.006098 1.011437 1.012960
Std.Err. 4.807407e-17 0.008 0.001052 0.006098 0.002844 0.002313
leaf[7] leaf[8] leaf[9]
Coef. 1.009091 1.036096 1.058667
Std.Err. 0.002863 0.007082 0.012725
LIVING leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] leaf[7] \
Coef. 1.00000 1.072000 1.012718 1.060976 1.017155 1.069816 1.085455
Std.Err. 0.01039 0.025843 0.003608 0.020642 0.005965 0.006964 0.010913
leaf[8] leaf[9]
Coef. 1.160428 1.200000
Std.Err. 0.017986 0.031595
OTHFN leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] leaf[7] \
Coef. 0.015544 0.0 0.069713 0.109756 0.060758 0.127926 0.223636
Std.Err. 0.008927 0.0 0.006280 0.028704 0.007494 0.007965 0.015883
leaf[8] leaf[9]
Coef. 0.201872 0.384000
Std.Err. 0.019956 0.036681
RECRM leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] leaf[7] \
Coef. 0.0 0.032000 0.038625 0.091463 0.031451 0.070652 0.125455
Std.Err. 0.0 0.015805 0.004236 0.022579 0.004882 0.005372 0.010397
leaf[8] leaf[9]
Coef. 0.212567 0.349333
Std.Err. 0.015897 0.028163
CLIMB leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 2.308571e+00 2.308571e+00 2.261089 2.280418 2.253642 2.293378
Std.Err. 3.204938e-17 3.988039e-17 0.018633 0.019846 0.016414 0.008611
leaf[7] leaf[8] leaf[9]
Coef. 2.304161 2.317617 2.302415
Std.Err. 0.004208 0.012362 0.006156
ELEV leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. -6.000000e+00 -6.000000e+00 -5.567122 -5.908537 -5.551108 -5.880435
Std.Err. 5.127900e-16 2.392823e-16 0.036987 0.064621 0.046704 0.018774
leaf[7] leaf[8] leaf[9]
Coef. -5.960909 -5.959893 -5.981333
Std.Err. 0.015944 0.020058 0.018667
DIRAC leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.469150 1.520207 1.462422 1.425796 1.453864 1.402817
Std.Err. 0.022588 0.024104 0.007016 0.029282 0.009189 0.008810
leaf[7] leaf[8] leaf[9]
Coef. 1.303784 1.275952 1.217845
Std.Err. 0.016260 0.020886 0.030770
PORCH leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.155440 1.088000 1.111163 1.036585 1.067191 1.047241
Std.Err. 0.026148 0.025441 0.006824 0.014705 0.006696 0.004339
leaf[7] leaf[8] leaf[9]
Coef. 1.042727 1.028075 1.018667
Std.Err. 0.006101 0.006044 0.006999
AIRSYS leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 1.398964 1.120000 1.297221 1.243902 1.065046 1.068144
Std.Err. 0.035340 0.029182 0.009921 0.033636 0.006596 0.005153
leaf[7] leaf[8] leaf[9]
Coef. 1.041818 1.036096 1.029333
Std.Err. 0.006038 0.006825 0.008725
WELL leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. -0.709845 -0.584000 -0.894960 -0.853659 -0.896355 -0.876254
Std.Err. 0.050833 0.075506 0.010056 0.043459 0.012176 0.010065
leaf[7] leaf[8] leaf[9]
Coef. -0.855455 -0.879679 -0.837333
Std.Err. 0.015858 0.017400 0.028645
WELDUS leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 4.507772 4.176000 4.762600 4.689024 4.802716 4.763378
Std.Err. 0.094403 0.144608 0.020549 0.083221 0.022765 0.019461
leaf[7] leaf[8] leaf[9]
Coef. 4.699091 4.763369 4.696000
Std.Err. 0.031655 0.034293 0.054157
STEAM leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. -0.129534 0.224000 -0.091851 -0.048780 -0.007148 0.035953
Std.Err. 0.098258 0.132404 0.029913 0.109344 0.037755 0.029171
leaf[7] leaf[8] leaf[9]
Coef. 0.035455 0.163102 -0.002667
Std.Err. 0.043003 0.053480 0.072981
OARSYS leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. -1.233161 0.952000 -0.409797 0.024390 1.425304 1.349498
Std.Err. 0.280641 0.231922 0.079011 0.268272 0.052730 0.041123
leaf[7] leaf[8] leaf[9]
Coef. 1.505455 1.34492 1.354667
Std.Err. 0.048562 0.05485 0.070740
noise1 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] leaf[7] \
Coef. 0.505618 0.508176 0.501445 0.50980 0.508980 0.498352 0.506366
Std.Err. 0.019987 0.026851 0.006171 0.02291 0.007757 0.005849 0.008779
leaf[8] leaf[9]
Coef. 0.498214 0.489948
Std.Err. 0.010782 0.015011
noise2 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.479330 0.510887 0.490818 0.506432 0.503823 0.491863
Std.Err. 0.021813 0.024629 0.006199 0.022006 0.007677 0.005916
leaf[7] leaf[8] leaf[9]
Coef. 0.519609 0.510273 0.522781
Std.Err. 0.008804 0.010675 0.014784
noise3 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.531553 0.520926 0.503041 0.513428 0.495849 0.502136
Std.Err. 0.020642 0.025942 0.006234 0.024108 0.007680 0.005939
leaf[7] leaf[8] leaf[9]
Coef. 0.497612 0.507676 0.498867
Std.Err. 0.008658 0.010623 0.014714
noise4 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.523838 0.508204 0.501693 0.490069 0.491062 0.496855
Std.Err. 0.020465 0.025079 0.006255 0.023845 0.007588 0.005855
leaf[7] leaf[8] leaf[9]
Coef. 0.512434 0.511926 0.499861
Std.Err. 0.008656 0.010537 0.015507
noise5 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.478568 0.523951 0.499522 0.507624 0.496674 0.500685
Std.Err. 0.021662 0.025191 0.006281 0.022255 0.007758 0.005944
leaf[7] leaf[8] leaf[9]
Coef. 0.503707 0.486443 0.484459
Std.Err. 0.008934 0.010450 0.015176
noise6 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.476431 0.498303 0.505307 0.499575 0.510473 0.508335
Std.Err. 0.020660 0.026290 0.006271 0.022161 0.007732 0.005895
leaf[7] leaf[8] leaf[9]
Coef. 0.506212 0.497468 0.493743
Std.Err. 0.008799 0.010308 0.015215
noise7 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.466509 0.532502 0.496970 0.518808 0.498091 0.503088
Std.Err. 0.020272 0.026065 0.006161 0.023536 0.007586 0.005869
leaf[7] leaf[8] leaf[9]
Coef. 0.513389 0.509192 0.506994
Std.Err. 0.008932 0.010350 0.014708
noise8 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.467514 0.531026 0.500346 0.504115 0.500933 0.495891
Std.Err. 0.019916 0.023795 0.006282 0.022729 0.007797 0.005931
leaf[7] leaf[8] leaf[9]
Coef. 0.491334 0.504812 0.519548
Std.Err. 0.008564 0.010536 0.014868
noise9 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.468098 0.526925 0.495539 0.529444 0.497031 0.505148
Std.Err. 0.021758 0.025539 0.006286 0.022109 0.007718 0.005907
leaf[7] leaf[8] leaf[9]
Coef. 0.494763 0.507972 0.511789
Std.Err. 0.008594 0.010442 0.014352
noise10 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.478180 0.500685 0.500060 0.472976 0.500191 0.511017
Std.Err. 0.020324 0.026903 0.006198 0.020793 0.007517 0.005885
leaf[7] leaf[8] leaf[9]
Coef. 0.500824 0.506995 0.499019
Std.Err. 0.008697 0.010502 0.015238
noise11 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.489795 0.488485 0.492516 0.509673 0.515484 0.508793
Std.Err. 0.020479 0.026809 0.006266 0.022111 0.007814 0.005892
leaf[7] leaf[8] leaf[9]
Coef. 0.502809 0.505733 0.491129
Std.Err. 0.008781 0.010552 0.014998
noise12 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.496124 0.547064 0.500455 0.471864 0.500168 0.501219
Std.Err. 0.019757 0.025711 0.006398 0.020903 0.007672 0.005918
leaf[7] leaf[8] leaf[9]
Coef. 0.500728 0.521672 0.494793
Std.Err. 0.008546 0.010593 0.014908
noise13 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.494888 0.535293 0.504892 0.479535 0.498929 0.497969
Std.Err. 0.020970 0.025177 0.006226 0.022273 0.007703 0.005880
leaf[7] leaf[8] leaf[9]
Coef. 0.484956 0.488564 0.525039
Std.Err. 0.008924 0.010471 0.014502
noise14 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.502771 0.511858 0.492756 0.485773 0.484064 0.506386
Std.Err. 0.020405 0.026618 0.006238 0.023378 0.007688 0.005918
leaf[7] leaf[8] leaf[9]
Coef. 0.491079 0.506982 0.510278
Std.Err. 0.008691 0.010477 0.015145
noise15 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.472543 0.528618 0.507714 0.515404 0.493721 0.504659
Std.Err. 0.020178 0.027276 0.006296 0.022529 0.007811 0.005896
leaf[7] leaf[8] leaf[9]
Coef. 0.502755 0.505887 0.533510
Std.Err. 0.008781 0.010675 0.014998
noise16 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.507393 0.484206 0.508391 0.476947 0.508548 0.496021
Std.Err. 0.020754 0.023525 0.006304 0.024211 0.007776 0.005903
leaf[7] leaf[8] leaf[9]
Coef. 0.515021 0.506695 0.484385
Std.Err. 0.008648 0.010293 0.015362
noise17 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.489426 0.471092 0.506304 0.494265 0.503826 0.502336
Std.Err. 0.019743 0.026462 0.006370 0.021789 0.007648 0.005893
leaf[7] leaf[8] leaf[9]
Coef. 0.491715 0.520289 0.502923
Std.Err. 0.008787 0.010738 0.014807
noise18 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.517420 0.501618 0.506690 0.514725 0.500758 0.501080
Std.Err. 0.020522 0.026708 0.006223 0.022547 0.007592 0.005993
leaf[7] leaf[8] leaf[9]
Coef. 0.500188 0.506352 0.487323
Std.Err. 0.008384 0.010230 0.015278
noise19 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.467595 0.508217 0.504449 0.509105 0.511728 0.498591
Std.Err. 0.021083 0.026840 0.006173 0.022455 0.007697 0.005811
leaf[7] leaf[8] leaf[9]
Coef. 0.500900 0.514904 0.492103
Std.Err. 0.008506 0.010683 0.014820
noise20 leaf[1] leaf[2] leaf[3] leaf[4] leaf[5] leaf[6] \
Coef. 0.490588 0.465721 0.508434 0.535436 0.498242 0.507797
Std.Err. 0.020553 0.024379 0.006266 0.022370 0.007577 0.005956
leaf[7] leaf[8] leaf[9]
Coef. 0.503339 0.488032 0.496959
Std.Err. 0.008697 0.010667 0.015243
Finally, as we did in the linear model case, we can use the same code for an annotated version of the same information. Again, we ordered the rows in decreasing order based on an estimate of the relative variance “explained” by leaf membership: \(Var(E[X_i|L_i]) / Var(X_i)\), where \(L_i\) represents the leaf.
df = pd.DataFrame()
for var_name in covariates:
form2 = var_name + " ~ " + "0" + "+" + "leaf"
ols = smf.ols(formula=form2, data=data1).fit(cov_type = 'HC2').summary2().tables[1].iloc[:, 0:2]
# Retrieve results
toget_index = ols["Coef."]
index = toget_index.index
cova1 = pd.Series(np.repeat(var_name,num_leaves), index = index, name = "covariate")
avg = pd.Series(ols["Coef."], name="avg")
stderr = pd.Series(ols["Std.Err."], name = "stderr")
ranking = pd.Series(np.arange(1,num_leaves+1), index = index, name = "ranking")
scaling = pd.Series(norm.cdf((avg - np.mean(avg))/np.std(avg)), index = index, name = "scaling")
data2 = pd.DataFrame(data=x_test, columns= covariates)
variation1= np.std(avg) / np.std(data2[var_name])
variation = pd.Series(np.repeat(variation1, num_leaves), index = index, name = "variation")
labels = pd.Series(round(avg,2).astype('str') + "\n" + "(" + round(stderr, 3).astype('str') + ")", index = index, name = "labels")
# Tally up results
df1 = pd.DataFrame(data = [cova1, avg, stderr, ranking, scaling, variation, labels]).T
df = df.append(df1)
# a small optional trick to ensure heatmap will be in decreasing order of 'variation'
df = df.sort_values(by = ["variation", "covariate"], ascending = False)
df = df.iloc[0:(8*num_leaves), :]
df1 = df.pivot(index = "covariate", columns = "ranking", values = ["scaling"]).astype(float)
labels = df.pivot(index = "covariate", columns = "ranking", values = ["labels"]).to_numpy()
# plot heatmap
ax = plt.subplots(figsize=(18, 10))
ax = sns.heatmap(df1,
annot=labels,
annot_kws={"size": 12, 'color':"k"},
fmt = '',
cmap = "YlGnBu",
linewidths=0,
xticklabels = ranking)
plt.tick_params( axis='y', labelsize=15, length=0, labelrotation=0)
plt.tick_params( axis='x', labelsize=15, length=0, labelrotation=0)
plt.xlabel("Leaf (ordered by prediction, low to high)", fontsize= 15)
plt.ylabel("")
ax.set_title("Average covariate values within leaf", fontsize=18, fontweight = "bold")
Text(0.5, 1.0, 'Average covariate values within leaf')
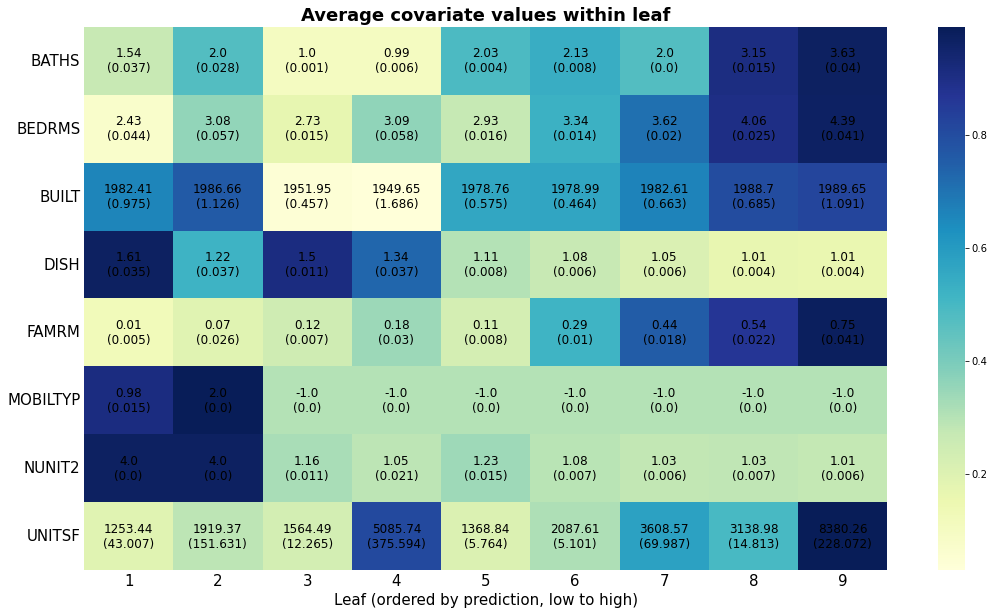
2.2.3. Forest#
Forests are a type of ensemble estimators: they aggregate information about many decision trees to compute a new estimate that typically has much smaller variance.
At a high level, the process of fitting a (regression) forest consists of fitting many decision trees, each on a different subsample of the data. The forest prediction for a particular point \(x\) is the average of all tree predictions for that point.
One interesting aspect of forests and many other ensemble methods is that cross-validation can be built into the algorithm itself. Since each tree only uses a subset of the data, the remaining subset is effectively a test set for that tree. We call these observations out-of-bag (there were not in the “bag” of training observations). They can be used to evaluate the performance of that tree, and the average of out-of-bag evaluations is evidence of the performance of the forest itself.
For the example below, we’ll use the regression_forest function of the R package grf. The particular forest implementation in grf has interesting properties that are absent from most other packages. For example, trees are build using a certain sample-splitting scheme that ensures that predictions are approximately unbiased and normally distributed for large samples, which in turn allows us to compute valid confidence intervals around those predictions. We’ll have more to say about the importance of these features when we talk about causal estimates in future chapters. See also the grf website for more information.
from sklearn.inspection import permutation_importance
from sklearn.ensemble import RandomForestRegressor
forest = RandomForestRegressor(n_estimators=200, oob_score=True)
#x_train, x_test, y_train, y_test = train_test_split(XX.to_numpy() , Y, test_size=.3)
forest.fit(x_train, y_train)
# Retrieving forest predictions
rf_pred = forest.predict(x_test)
# Evaluation
mse = mean_squared_error(y_test, rf_pred)
print("Forest MSE:", mse)
Forest MSE: 0.5873930432041589
The fitted attribute feature_importances_ computes the decrease in node impurity weighted by the probability of reaching that node. The node probability can be calculated by the number of samples that reach the node, divided by the total number of samples. The higher the value the more important the feature.
feature_importance = pd.DataFrame(forest.feature_importances_, index=covariates, columns= ["importance"])
importance = feature_importance.sort_values(by=["importance"], ascending=False)
importance[:10].T
| UNITSF | NUNIT2 | BATHS | MOBILTYP | LOT | noise2 | noise10 | noise18 | noise14 | noise17 | |
|---|---|---|---|---|---|---|---|---|---|---|
| importance | 0.147069 | 0.112232 | 0.06445 | 0.051078 | 0.033354 | 0.029163 | 0.027714 | 0.026012 | 0.025877 | 0.024181 |
plt.figure(figsize=(10,7))
sns.barplot(importance.index[:10],importance.importance[:10])
plt. xticks(rotation= 90, fontsize=15)
plt.yticks(fontsize=10)
plt.ylabel("Importance",fontsize=15)
plt.title("Variable Importance", fontsize=15)
Text(0.5, 1.0, 'Variable Importance')
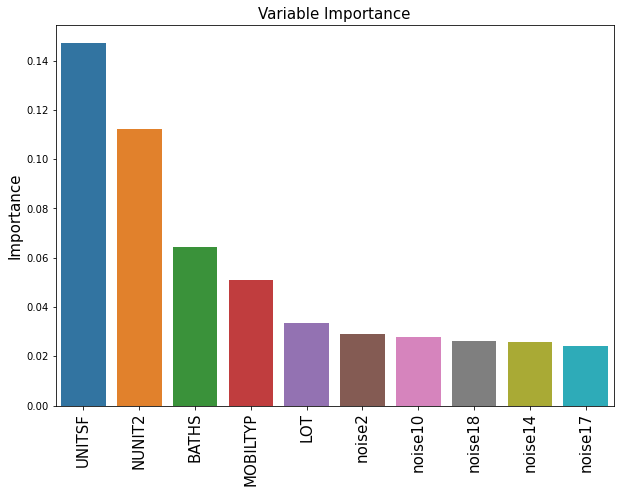
All the caveats about interpretation that we mentioned above apply in a similar to forest output.
2.3. Further reading#
In this tutorial we briefly reviewed some key concepts that we recur later in this tutorial. For readers who are entirely new to this field or interested in learning about it more depth, the first few chapters of the following textbook are an acccessible introduction:
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to statistical learning (Vol. 112, p. 18). New York: springer. Available for free at the authors’ website.
Some of the discussion in the Lasso section in particular was drawn from Mullainathan and Spiess (JEP, 2017), which contains a good discussion of the interpretability issues discussed here.
There has been a good deal of research on inference in high-dimensional models, Although we won’t be covering in depth it in this tutorial, we refer readers to Belloni, Chernozhukov and Hansen (JEP, 2014). Also check out the related R package hdm, developed by the same authors, along with Philipp Bach and Martin Spindler.